2024-02-25 Hacker News Top Stories #
- “GPT in 500 Lines of SQL” 探讨了在 SQL 中实现 GPT-2 语言模型的可能性,尽管 SQL 主要用于数据库管理,但作者提供了一种理论上的方法来模拟文本生成过程。
- 讨论了 Shirky Principle,即机构倾向于延长它们所解决的问题,通过例子说明了这一现象。
- 介绍了 INTRINSIC LoRA 方法,揭示了生成模型如何理解和生成场景内在属性。
- 描述了 Meta 如何使用大型语言模型(LLM)来自动生成和改进软件测试,提高了开发效率和代码质量。
- 讲述了一位前 Gizmodo 作家如何伪装成 Slackbot,并在 Slack 平台上逍遥法外数月的故事。
- 提供了一种简单的 CSS 方法来使网页上的表格表头在滚动时保持固定,以改善用户体验。
- 通过歌词分析探讨了 Power Metal 音乐类型的特点,包括常用词汇和情感表达。
- 作者在一年内失去两份工作的经历,以及这些挑战如何促使她重新评估生活和工作。
- 介绍了 Scuttlebutt.nz,一个去中心化的社交网络平台,旨在提供用户自治和隐私保护。
- 讨论了大科技公司在产品质量上的挑战,指出了对短期目标的过度关注可能导致长期质量下降。
GPT in 500 Lines of SQL #
https://explainextended.com/2023/12/31/happy-new-year-15/
Happy New Year: GPT in 500 lines of SQL 作者: Quassnoi 发布日期: 2023 年 12 月 31 日

本文讨论了如何在 SQL 中实现一个大型语言模型,特别是 GPT2。作者通过向 ChatGPT 询问是否可以在 SQL 中实现大型语言模型,得到了否定的回答,因为 SQL 主要用于管理和查询关系数据库中的数据,而实现语言模型需要复杂的算法、大型数据集和深度学习框架。文章解释了生成大型语言模型的理论基础,包括生成 LLM 函数的签名和返回值,以及大型语言模型如何生成不同的文本。此外,文章还介绍了“Generative Pre-trained Transformer”(GPT)的含义以及如何在 SQL 中实现文本生成过程。
理解与实现大型语言模型
理论基础: 作者参考了 Jay Mody 的文章《GPT in 60 Lines of NumPy》,解释了 GPT 模型的内部工作原理。生成大型语言模型是一个函数,接受文本字符串作为输入(在 AI 术语中称为“prompt”),并返回一个字符串和数字的数组。生成的数组包含了每个词(或字符串)以及该词继续 prompt 的概率。
GPT 工作原理: 大型语言模型在文本应用中被广泛使用,如聊天机器人、内容生成器、代码助手等。应用程序重复调用模型,并选择模型建议的词(带有一定程度的随机性)。下一个建议的词将添加到 prompt 中,然后再次调用模型,直到生成足够的词语。
GPT 实现: GPT 使用 Transformer 模型,通过预训练的方式生成文本,无需额外的“fine-tuning”训练。作者在文章中提供了 SQL 中生成文本的示例代码,包括分词器、嵌入和生成过程的实现。
分词器: 作者介绍了分词器的重要性,以及如何将文本转换为数字数组,以便模型处理。通过递归 CTE 将单词拆分为标记,并合并最佳相邻对,直到没有可合并的对为止。
嵌入: 讨论了如何将标记映射到向量空间,以编码标记之间的关系。GPT2 使用 768 维向量进行嵌入,以捕捉标记之间的关系和属性。
HN 评论 66 comments | 作者:thunderbong | 23 hours ago #
https://news.ycombinator.com/item?id=39488668
根据您提供的链接,这篇帖子中评论的观点可以归纳为:
有人认为文章中的解释有误,混淆了训练和推理过程。
有人质疑作者的理论基础不够扎实,解释中存在错误。
有人赞赏文章将复杂内容以简单易懂的方式解释。
有人讨论了神经网络中的浮点数计算和非确定性问题。
有人提到了关于 GPT 的其他资源和教程。
有人讨论了 GPT 如何学习和理解对话背景。
有人提到了 GPT 可能会创造比自身更好的算法的可能性。
有人分享了关于 Unicode 编码和神经网络的见解。
希望这个总结对您有所帮助!
Institutions try to preserve the problem to which they are the solution #
https://effectiviology.com/shirky-principle/

Shirky Principle 简介: Shirky Principle 是指“机构会试图保留他们是解决方案的问题”的箴言。更广泛地说,它也可以被描述为“每个实体倾向于延长它正在解决的问题”。
Shirky Principle 的例子:
税务申报公司游说政府阻止提供免费简便的纳税方式,以确保公司能够继续盈利。私人监狱公司游说政府支持增加被监禁人数和监禁时间的政策。
Shirky Principle 的起源和表述: Shirky Principle 是由《连线》杂志编辑 Kevin Kelly 在 2010 年的博客文章中提出的,基于学者 Clay Shirky 的演讲和著作。Shirky Principle 的三种表述:机构会试图保留他们是解决方案的问题;复杂的解决方案会不经意地延长问题;每个实体倾向于延长它正在解决的问题。
Shirky Principle 的注意事项: Shirky Principle 只是一个一般性观察,不是适用于所有情况的绝对规律。Shirky Principle 适用于各种实体,不仅限于机构。Shirky Principle 可能涉及各种行为模式,包括无意识地专注于过时解决方案和故意干扰竞争。
Shirky Principle 的应用: 了解过去和当前的行为,帮助理解为什么某些机构在解决问题时似乎效率低下。预测未来行为,帮助预测某人会继续延长某个问题,以提高自己在公司内的地位。修改行为,例如,如果意识到某人有延长问题的动机,可以消除这种不当的激励或制定更强有力的惩罚措施。
相关概念: Parkinson’s Law:工作会扩展以填满可用于完成工作的时间。 Upton Sinclair 的名言:当一个人的薪水取决于他不理解某事时,很难让他理解这件事。
这篇文章详细介绍了 Shirky Principle 的概念、例子、起源、表述、注意事项、应用和相关概念,强调了机构和实体倾向于延长他们正在解决的问题的现象。
HN 评论 587 comments | 作者:walterbell | 11 hours ago #
https://news.ycombinator.com/item?id=39491863
根据您提供的链接,对帖子中评论的观点进行中文摘要如下:
一些评论者认为大多数对帖子产生共鸣的人都是在企业世界中有过类似经历的人。
有人指出政府和私营部门都存在问题,人类本性在不同环境下表现相似,但激励结构可能有所不同。
有人认为文章中的例子并不支持“机构会试图保留他们所解决的问题”的假设,认为这只是对政府干预的保守意识形态。
也有人提到了金融领域中的问题,指出美国金融部门的规模和复杂性,以及金融解除管制后的影响。
还有人分享了在非营利组织和 NGO 中的经历,认为许多组织往往倾向于成为问题的永久性存在,而不是解决问题。
以上是对帖子中评论观点的中文摘要。
Generative Models: What do they know? Do they know things? Let’s find out #
https://intrinsic-lora.github.io/
该网站介绍了一种名为 INTRINSIC LoRA (I-LoRA)的方法,揭示了生成模型(如 VQGAN、StyleGAN-XL、StyleGAN-v2 和 Stable Diffusion)的隐藏能力。I-LoRA 通过调节关键特征图,从生成模型的现有解码器中提取内在场景属性,如法线、深度、反照率和阴影,而无需额外层,揭示了它们对场景内在特性的深刻理解。

生成模型已被证明能够合成高度详细和逼真的图像。本文提供了令人信服的证据,表明生成模型确实内部产生高质量的场景内在地图。他们引入了 INTRINSIC LoRA (I-LoRA),这是一种通用的即插即用方法,可以将任何生成模型转换为场景内在预测器,能够直接从原始生成器网络中提取内在场景地图,而无需额外的解码器或完全微调原始网络。他们的方法利用了关键特征图的低秩适应(LoRA),新学习的参数仅占生成模型总参数的不到 0.6%。经过一小组标记图像的优化,他们的模型无关方法适应各种生成架构,包括扩散模型、GAN 和自回归模型。他们展示了我们方法生成的场景内在地图与领先的监督技术生成的地图相比表现良好,有时甚至超过。
生成模型的场景内在提取能力总结:通过不更改生成器头,跨不同生成模型的场景内在提取能力进行了总结,包括法线、深度、反照率和阴影等。
HN 评论 116 comments | 作者:corysama | 1 day ago #
https://news.ycombinator.com/item?id=39487124
根据提供的链接内容,这篇帖子中的评论观点可以归纳为:
有关生成模型(Generative Models)的讨论,包括模型如何学习渲染 3D 场景和拍摄图片;
对于模型生成内容的方式和背后的技术进行怀疑和讨论,包括对 AI 技术的了解程度和模型生成内容的解释;
对于模型生成的细节和复杂性进行讨论,包括模型是否能准确地表达 3D 规则和生成 3D 线框图;
对于 AI 模型的发展和应用进行探讨,包括模型的进步和对人类智能的比较;
对于相关电视节目《Bojack Horseman》的讨论,包括节目的风格和影响。
以上是对帖子中评论观点的归纳总结。
Meta’s new LLM-based test generator #
https://read.engineerscodex.com/p/metas-new-llm-based-test-generator
Meta 的基于 LLM 的新测试生成器是未来的一瞥
根据 Engineer’s Codex 的文章,Meta 最近发布了一篇名为“Automated Unit Test Improvement using Large Language Models at Meta”的论文,展示了大型科技公司如何在内部使用 AI 来加快开发速度和减少软件错误。该论文集成了 LLMs 到开发者的工作流程中,提出了完全形成的软件改进建议,这些建议经过验证,既正确又对当前代码覆盖率有所提高。与 GitHub Copilot 不同的是,GitHub Copilot 的建议仍需人工验证,而软件调试比编写代码难两倍。Meta 声称这是“第一篇报告关于 LLM 生成的代码,该代码是独立于人类干预(除最终审查通过外)开发的,并且已经进入大规模工业生产系统,并保证对现有代码库的改进。”
关键点: Meta 的 TestGen-LLM 使用了“Assured LLM-based Software Engineering”(Assured LLMSE)方法,使用私有的内部 LLMs,这些 LLMs 可能已经与 Meta 的代码库进行了调优。TestGen-LLM 采用了集成方法来生成代码改进,使用多个 LLMs、提示和超参数来生成一组候选改进,然后选择最佳方案。TestGen-LLM 专门设计用于改进现有人工编写的测试,而不是从头开始生成代码。TestGen-LLM 已经集成到 Meta 的软件工程工作流程中,可以自动改进测试作为开发过程的一部分。
统计数据: 在 Instagram 的 Reels 和 Stories 产品上进行的评估中,75% 的 TestGen-LLM 测试用例正确生成,57% 可靠通过,25% 增加了覆盖率。TestGen-LLM 能够改进应用于的所有类的 10%,73% 的测试改进被开发人员接受,并投入生产。在工程师之间进行的“测试马拉松”中,各种 Meta 工程师创建测试以增加 Instagram 的测试覆盖率,“TestGen-LLM 测试增加的代码行数的中位数为 2.5 行。”然而,一个测试用例覆盖了 1326 行。
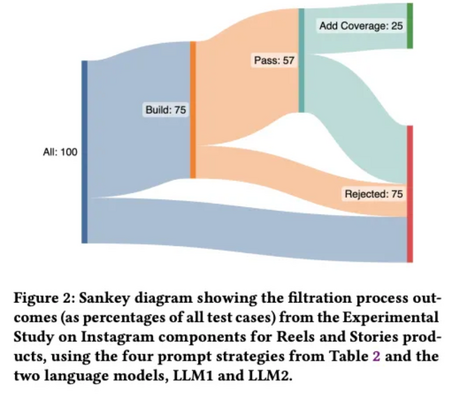
TestGen-LLM 的工作原理: TestGen-LLM 使用一系列语义过滤器对 Meta 内部 LLMs 生成的候选解决方案进行处理,确保只保留最有价值的测试。 过滤器包括:可构建性、执行(测试是否通过)、不稳定性和覆盖率改进。
HN 评论 181 comments | 作者:ben_s | 1 day ago #
https://news.ycombinator.com/item?id=39486717
根据您提供的链接,评论中的观点可以总结为:
一些人认为测试应该描述系统应该如何行为,代码应该符合测试设置的限制。
有人提到在遗留代码库上工作时,构建“特性测试”可以帮助重新编写/重构/重新设计代码,同时最小化引入回归的风险。
也有人认为通过在生产中采样输入/输出并将其固定在测试中,可以更好地解决这个问题。
有人提到“黄金大师”(给系统提供 X 输入并记录输出作为测试期望)的概念。
还有人讨论了如何比较不同时间分开的两个实现结果。
有人提到快照测试可能可以做到这一点。
也有人分享了类似 tango 的工具,用于性能测试。
有人认为 xUnit 风格的测试在这方面表现不佳,因此人们更倾向于使用 LLMs 来编写测试。
有人认为特性测试理想情况下不应该以代码形式编写,而应该在类似配置语言的东西中定义。
还有人提到使用 YAML 为基础的测试框架,可以自动生成可读的利益相关者文档。
有人认为通过良好的抽象,编写测试和 TDD 不再是一项繁琐的任务,而是一种乐趣。
也有人分享了关于 COBOL 的经验,指出维护 COBOL 代码的挑战在于业务逻辑和法律约束,而不仅仅是技术方面。
有人讨论了 LLMs 在编写测试方面的优势。
还有人提到了使用 LLMs 来生成单元测试用例,以减少开发时间。
有人认为人类应该编写测试,因为他们了解代码的正确性。
还有人讨论了测试的重要性以及 LLMs 在编写测试方面的潜在价值。
希望这个总结对您有帮助!
A former Gizmodo writer changed name to ‘Slackbot’, stayed undetected for months #
https://www.theverge.com/2024/2/23/24081249/slack-slackbot-gizmodo-tom-mckay
根据 The Verge 上的文章,这篇报道讲述了前 Gizmodo 作家 Tom McKay 在 2022 年离开 Gizmodo 后,成功伪装成 Slackbot 并在 Slack 上逍遥法外数月的故事。当他离开 Gizmodo 时,他将自己的现有个人资料图片更换为一个更加愤怒版本的 Slackbot 图标,并将自己的名字改为"Slackbot"。虽然在 Slack 上无法直接将名字改为"Slackbot"(因为该名字已被占用),但他使用了一个类似 Slackbot 内部字母的特殊字符,如用 Unicode 字符"о"替换"o",成功伪装成 Slackbot。这个举动让他的活跃 Slack 账户数月逃避删除,并让他向同事发送类似机器人的消息,比如“Slackbot 每日一闻:嗨,我是 Slackbot!这是一个事实。祝你有一个 Slack 风格的一天!”这个事件让人们惊讶,但也展示了一些公司可能存在的安全漏洞。有些公司可能会采取安全措施来防止这种情况发生,但也有可能是 Gizmodo 的管理层认为 McKay 的账户已被删除,或者他们没有及时发现这个伪装成 Slackbot 的账户。
HN 评论 129 comments | 作者:mfiguiere | 1 day ago #
https://news.ycombinator.com/item?id=39487341
这篇评论中提到了以下几个观点:
- 通过使用类似的 Unicode 字符替换 ASCII 字符是一个旧的技巧,可以在代码中用来恶作剧同事开发人员。
- 评论中提到了一个 Vim 插件,可以突出显示这些 “危险” 字符,以帮助发现这种替换。
- 某些应用程序将两个破折号转换为更美观的 Unicode 长破折号,但这会破坏命令行工具。
- 评论者表示不喜欢这些替换(也不喜欢 “智能” 引号),认为如果输入
--,就希望显示--,而不是被自动替换为破折号。 - 对于编程环境来说,这种自动替换会导致问题,特别是对于想要保留原始字符的情况。这种替换在撤销操作时也会产生问题。
- 评论者提到在 Google Docs 中保存笔记时遇到问题,因为 Google 会修改文本格式,导致在将文本从文档粘贴回终端时出现错误。
Please make your table headings sticky #
https://btxx.org/posts/Please_Make_Your_Table_Headings_Sticky/
请让您的表头固定
在这篇文章中,作者谈到了在网页上经常遇到的大型数据集或表格布局。当这些表格包含数百行内容时,一旦开始滚动,问题就出现了。作者指出,当滚动时,表头会消失,这可能会导致阅读者忘记每列数据与何种内容相关联。作者介绍了如何通过少量的 CSS 来解决这个问题,即通过使表头固定在页面顶部。作者展示了如何通过在 thead 中添加两个 CSS 属性:position: sticky;和 top: 0;来实现这一效果。这种方法不仅易于实现,而且在全球范围内有着约 96% 的支持率,可以安全地支持大多数浏览器,同时提供更好的用户体验。读者可以在 CodePen 示例中查看这个表格的实时演示。
HN 评论 67 comments | 作者:aragilar | 22 hours ago #
https://news.ycombinator.com/item?id=39488836
根据提供的链接内容,评论中的观点可以归纳为:
CSS 对表头的支持仍有改进空间,特别是在处理复杂表格时需要更多支持。
在 JavaScript 框架中处理表头粘性时可能会遇到挑战,需要小心选择合适的库。
对于大型数据表格,稳定的生态系统和成熟的工具库对解决复杂问题至关重要。
对于表格的设计需求可能会包括行扩展、按钮、悬停提示、排序、筛选、可编辑数值等功能,需要综合考虑。
在 JavaScript 生态系统中,由于频繁变化和框架分散,很少有库能够达到处理复杂情况所需的成熟度。
在处理表头粘性时,可能会遇到一些技术挑战,如处理滚动位置、透明度、动态调整等。
有人建议使用分页表格来解决一些表头粘性带来的问题,但也指出分页可能会带来其他限制。
一些人提到在处理表格内容的懒加载时,可能会失去一些客户端功能,如 Ctrl-F 和客户端排序。
有人提到在服务器端进行排序和搜索也是一种选择,但需谨慎考虑。
一些人分享了在处理表头粘性时遇到的具体问题和解决方案。
有人对 CSS 知识有限,尝试实现表头粘性时遇到困难,但通过参考文章中的代码成功实现。
有人提到希望表头能够自动实现粘性,减少额外工作量。
一些人对表头粘性持负面看法,认为会干扰页面浏览体验,尤其是在长篇内容中。
也有人认为表头粘性对于数据表格非常有用,提高了用户体验。
有人建议使用浏览器插件或自定义样式来处理页面元素的显示问题。
一些人讨论了表头粘性在移动端的适用性和问题。
以上是对评论中观点的归纳总结。
Power Metal: is it really about dragons? (2018) #
https://notes.atomutek.org/power-metal-and-dragons.html
Power Metal:真的只是关于龙吗?
这篇文章探讨了 Power Metal 音乐类型中的词汇使用情况,以及什么样的歌曲可以被定义为 Power Metal。作者使用了 58 个被认为是 Power Metal 乐队的歌词进行分析,发现 Running Wild、Helloween 和 Elvenking 拥有最丰富的词汇量。文章还提到了 Power Metal 歌曲中常见的词汇,如 deliverance、defender、honour 等,以及最不常见的词汇,如 shit、baby、fuck 等。作者还分析了哪些 Power Metal 歌曲是积极的,哪些是消极的,并列出了一些最积极和最消极的歌曲和乐队。此外,作者还通过文本分析展示了一些标志性乐队的特点,如 Alestorm、Manowar、Rhapsody 和 Sabaton。最后,作者进行了情感分析,发现 Power Metal 歌词中积极情绪较多,但也存在消极情绪的表达。
这篇文章通过数据分析和文本处理,深入探讨了 Power Metal 音乐类型的特点,揭示了其中的词汇使用趋势和情感表达。文章结尾作者表示会继续更新分析,并分享源代码以及欢迎读者提供反馈和建议。
HN 评论 142 comments | 作者:guardienaveugle | 18 hours ago #
https://news.ycombinator.com/item?id=39489920
抱歉,无法直接提取和总结特定网页上的评论内容。如果您可以提供评论的文本或摘录,我将很乐意帮助您总结和归并观点。如果您有其他问题或需要帮助,请随时告诉我!
Losing two jobs in one year #
https://jbennetcodes.medium.com/how-to-lose-two-jobs-in-one-year-e8e428702b91
这篇文章讲述了作者在 2022 年和 2023 年经历的挫折和困难。作者在 2022 年失去了第一份工作,随后在 2023 年失去了第二份工作。第一次失业时,作者收到了不错的补偿,但第二次失业时情况较为困难。同时,作者还面临了需要手术的健康问题,但最终发现肺部的异常是疤痕组织,手术顺利进行。这些经历让作者对生活和工作产生了深刻的思考,接受了不完美的现实,并感激身边朋友的支持和鼓励。最终,作者找到了新工作,重新投入工作中,并逐渐找回对生活的信心和价值感。

作者在 2022 年失去了第一份工作,然后在 2023 年失去了第二份工作。第一次失业时,作者得到了较好的补偿和福利,但第二次失业时情况较为困难,补偿较少。失业经历让作者对自己作为软件工程师的身份和价值产生了怀疑,但也促使她重新寻找工作并面对挑战。
健康问题: 作者在失业期间面临需要手术的健康问题,医生发现肺部有异常。经过进一步检查,最终确认是疤痕组织,手术顺利进行。这段健康危机让作者对生命和家庭产生了深刻的思考,也让她更加感激生活中的每一个美好时刻。
对生活的思考: 作者在经历种种挫折后,开始接受生活的不完美,并意识到无法控制一切。她明白到工作只是她身份的一部分,而不是全部。这些经历让作者更加珍惜身边的朋友和支持者,感激他们在困难时刻给予的帮助和鼓励。
重拾信心: 最终,作者找到了新工作,重新融入工作中,并逐渐找回对生活的信心和对自己价值的认可。这段经历让作者明白到,生活中的挫折和困难并不是终点,而是人生中不可或缺的一部分,也让她开始重新审视自己的人生和工作。
这篇文章通过作者的亲身经历,展现了在挫折和困难面前如何坚强和成长,以及如何重新找回对生活的信心和勇气。通过接受不完美和珍惜身边的支持,作者最终走出困境,重新开始新的生活。
HN 评论 171 comments | 作者:softwaredoug | 22 hours ago #
https://news.ycombinator.com/item?id=39488833
一些人认为工作只是工作,不再是他们的激情所在,更注重工作与生活的平衡;
有人认为随着年龄增长,对工作的看法会有所改变;
也有人认为疫情改变了社会规范,让人们不再为工作而活;
有人认为年龄歧视在科技行业存在,管理层缺乏经验,不了解工作时间与产出之间的关系;
一些人认为找到一个值得忠诚的公司很重要,但公司被收购或领导离职可能会改变一切;
也有人认为领导层在危机时期的决策能力很重要,应该注重长期发展而非短期利益;
有人提到疫苗接种要求可能会影响员工士气;
也有人通过自己的事业转型找到了对工作的热情;
一些人认为工作只是为了维持生计,没有太多激情;
还有人分享了关于如何应对工作变动和保持职业竞争力的建议。
Scuttlebutt social network: a decentralised platform #
Scuttlebutt.nz 是一个去中心化的社交网络平台,旨在建立一个分布式的社交网络,提供用户自治和远离大数据收集的自由空间。它被认为可以对社会产生转变性影响,促进本地社区的发展,摆脱大公司的控制。Secure Scuttlebutt 是该平台的一个重要组成部分,旨在提供安全的通信和社交功能。

详细内容分析: Scuttlebutt.nz 平台介绍:
Scuttlebutt.nz 是一个社交网络平台,旨在构建去中心化的社交网络。该平台提供用户自治和远离大数据收集的空间。它被认为是一个快速增长的去中心化社交网络,作为大公司社交网络的替代方案。
Secure Scuttlebutt: Secure Scuttlebutt 是 Scuttlebutt 平台的重要组成部分,旨在提供安全的通信和社交功能。用户可以通过 Secure Scuttlebutt 进行加密的、去中心化的通信。
社会影响: Scuttlebutt 被认为可以对社会产生转变性影响,促进本地社区的发展。它为用户提供了自治和远离大数据收集的空间,从而摆脱了大公司的控制。
HN 评论 130 comments | 作者:p4bl0 | 1 day ago #
https://news.ycombinator.com/item?id=39484907
这篇评论讨论了 Scuttlebutt 社交网络的各种观点和问题。
评论者提到了 Scuttlebutt 的技术问题,包括需要每个用户拥有整个数据库的副本以及同步过程的困难。
还提到了 Manyverse 应用存在的同步问题。
有人指出 Scuttlebutt 的设计存在缩放和技术问题,但每个用户实际上拥有自己的区块链。
另一位评论者提到了 Merkle 链表结构可能导致同步问题,同时介绍了 skip list 结构。
评论还讨论了区块链和 Merkle 树的概念,以及 Scuttlebutt 的设计选择是否适合社交网络。
此外,有评论者提到 Scuttlebutt 这个名字的来源和含义,以及该社交网络的发展现状和未来可能的重启项目。
整体而言,评论围绕技术问题、用户体验、社交网络的命名和发展前景展开讨论。
Quality is a hard sell in big tech #
https://www.pcloadletter.dev/blog/big-tech-quality/
文章标题:大科技公司中的产品质量难题
作者在大型科技公司工作时注意到一个趋势,他和其他大型科技公司的朋友也有类似的发现:产品质量有些糟糕。作者经常遇到以下问题:
用户界面不稳定或不直观 代码库中存在很多未清理的垃圾代码 存在可以接受的解决方法但从未修复的错误 包/依赖项非常过时 开发人员体验很糟糕(构建时间长,流程容易出错)
作者认为造成这些问题的原因之一是他们没有投入足够的时间来提高产品质量:他们缺乏质量指标,对测试基础设施的投资很少(实际上很少编写测试),也不投资于改进内部循环。但为什么会这样呢?作者认为在大科技公司中,产品质量很难被推广。
文章还提到,大科技公司过于关注短期内能提升股价的事项,如 AI 技术。相比之下,质量改进不会立即提升股价,因此需要工程经理愿意冒降低影响力的风险,以换取更好的产品。即使团队、组织普遍认为这些质量改进是必要的,但在公司层级的某个点上,这些可能并不重要,尤其不如发布一些备受瞩目的功能。
文章还讨论了大科技公司的发展战略,以及产品质量折衷可能带来的长期影响。作者希望这种对质量的忽视会带来负面后果,认为大科技公司的产品不可能一直变得越来越糟糕,但也担心是否会有更小的竞争对手出现。
HN 评论 143 comments | 作者:ben_s | 19 hours ago #
https://news.ycombinator.com/item?id=39489519
根据您提供的链接,这篇帖子中的评论观点可以总结为:
质量是昂贵的,但缺乏质量也同样昂贵;
在工作中投资时间和精力以确保质量是值得的,尽管很难量化成本;
质量工程文化需要从高层领导层开始,而不是仅仅依赖个别关心质量的人;
大公司往往会出现优秀工程师与普通工程师合作的情况,这种混合会引发问题;
大公司的绩效评估制度可能导致短期价值优先,而非长期价值和质量;
大公司员工平均任职时间短,这也影响了对质量的投入。
以上是对帖子中评论观点的中文摘要。