Zed, a collaborative code editor, is now open source #
https://zed.dev/blog/zed-is-now-open-source
为什么要开源 Zed?首先,我们相信将 Zed 开源将使其成为最好的产品。我们的使命是构建世界上最先进的代码编辑器,并将其交到数百万开发者手中。这个问题涉及到很多方面,我们需要尽可能多的帮助。考虑到 Zed 的用户都是程序员,将 Zed 开放给最广泛的人才池是最合理的选择。
其次,我们认为开源将更有趣。软件的一个最喜欢的方面之一就是与人们的连接。我们不仅为我们所构建的东西感到自豪,也为我们构建的方式感到自豪。我们希望与大家分享 Zed 的内在美,并且我们相信在这个过程中我们会从大家身上学到很多,使它变得更好。
为了更好地与大家建立联系,我们推出了一个名为 Zed Channels 的新功能,它可以让世界各地的开发者通过共享链接实时编写代码。我们将利用 Channels 来运行一个名为 Fireside Hacks 的新项目,我们将在一个公共频道中实时开发 Zed,与任何出现的人一起工作。我们将尝试不同的形式,但我们希望这些定期的会话给我们所有人提供一个机会,让我们更好地了解彼此,超越静态的拉取请求。欢迎加入这个实验,提问、提建议,并与我们一起实时编码。我们期待与您见面!
开源 Zed 是否会影响商业成功?我们坚信,构建和维护世界上最好的编辑器的最佳方式是将其与可持续的商业模式联系起来。这是我们能够继续投资于全职团队来推动开发的唯一方式。有人可能会想知道,开源 Zed 是否会破坏这个目标。我们经过深思熟虑,认为开放性与商业成功并不矛盾。
我们更希望向您销售与您的编辑器无缝集成的服务,以提高您和您的团队的生产力,而不是向您销售专有的编辑器。Zed Channels 就是这样一个服务的例子。目前,任何人都可以免费使用它,但我们打算在测试期结束后开始对私人使用收费。提供服务器端计算来支持 AI 功能是另一种我们看到正在获得认可的商业化方案。
今天,我们开源了迄今为止我们编写的 100% 的代码。然而,将来我们可能仍然会提供针对商业和企业用例的专有产品,尽管我们始终打算将专有代码与开源代码相比仅占很小一部分。我们还打算确保我们产生收入的需求永远不会干扰您编写软件的需求。我们永远不会在您的代码编辑器中显示横幅广告,如果我们这样做了,您可以随时从源代码构建 Zed。
我们相信创造比我们捕获的价值更多的原则。开源是一个赌注,如果我们能够在 Zed 周围建立一个庞大的运动,我们的公司将找到机会捕获我们创造的一部分价值。
接下来的路线是什么?在某种程度上,这取决于您!但也可以说,我们仍然是一个小团队。我们希望在 2024 年大规模增加 Zed 的采用率,以便更多的开发者可以从中受益。我们根据用户反馈制定了一个公共路线图,我们认为这可以帮助我们实现这一目标。如果您的贡献有助于我们完成路线图,特别是靠前的项目,我们将更有可能为它们腾出时间。
总之,我们将在前进的过程中逐步解决问题,欢迎任何对贡献和学习感兴趣的人。如果您想参与其中,请查看我们的贡献指南,并在即将举行的 Fireside Hack 中打个招呼,如果您有时间的话。世界各地的开发者都需要一个更好的代码编辑器,我们很期待您加入我们的使命,推动技术的进步。在代码库中见!
HN 评论 316 comments | 作者:FeroTheFox | 8 hours ago #
https://news.ycombinator.com/item?id=39119835
根据您提供的链接,这篇帖子中的评论观点可以归纳如下:
对 Zed 的积极评价:
Zed 是一个非常响应迅速的协作代码编辑器,相比其他编辑器更加高效。
Zed 的搜索和替换功能得到改进,用户反馈得到了积极回应。
Zed 的调试语法树模式是一个很棒的功能,展示了其在底层比传统基于正则表达式的编辑器更先进的特性。
对 Zed 的期望和希望改进的方面:
对于协作工作流程和安全性方面的问题,希望能够更清楚地了解自托管聊天服务器和使用公司 OAuth 提供程序的可能性。
希望能够集成 ollama。
对于窗口大小和位置、语言服务器错误以及主题导入等问题,希望能够得到改进。
与其他编辑器的比较:
有人认为 Zed 和 VSCode 相比更加快速,但也有人认为 Emacs 29 配置适当时也能达到类似的响应速度。
有人提到 Sublime Text 在某些情况下会变得非常慢,但也有人对 Sublime Text 的改进表示肯定。
有人认为 Zed 在界面设计上更加专注和舒缓,相比其他编辑器更加集中注意力。
许多评论提到 Zed 的许可证选择和开源性质。
总体而言,大部分评论对 Zed 表示赞赏,认为它是一个快速、高效且专注的代码编辑器。同时,也有一些期望和改进的建议。
Waterway Map #
WaterwayMap.org 是一个基于 OpenStreetMap 的网站,提供了一个独特的拓扑视图,展示了水道和河流之间的连接关系。它显示了 OpenStreetMap 中的水道、河流、运河等自然水道以及命名的水道,并标注了可供船只和独木舟通行的水道。该网站的数据更新于 2024 年 1 月 23 日。
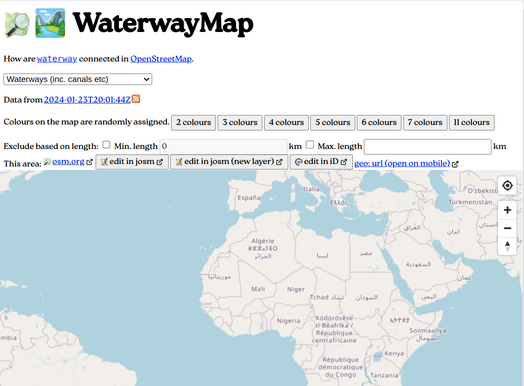
在地图上,水道和河流的颜色是随机分配的,可以选择 2 种、3 种、4 种、5 种、6 种、7 种或 11 种颜色进行显示。此外,还可以根据长度范围来排除显示在地图上的水道。网站提供了一些编辑工具,包括在 josm 中编辑、在 josm 中编辑(新图层)、在 iD 中编辑,以及在移动设备上打开 geo: url。
WaterwayMap.org 的数据是基于 OpenStreetMap 贡献者的数据,使用开放数据许可证。如果在水道的循环连接方面存在错误,可以通过报告问题来提供反馈。此外,网站还提供了社交媒体上的更新信息,可以通过#WaterwayMapOrg 和 @ amapanda@en.osm.town 进行关注。
请注意,以上摘要是根据访问的网页内容生成的,如有任何变动或更新,请以实际网站内容为准。
HN 评论 144 comments | 作者:wcedmisten | 1 day ago #
https://news.ycombinator.com/item?id=39110434
根据提供的链接,这篇帖子中的评论观点可以总结如下:
英国的运河系统是工业革命前建造的,用于快速和无损地运输煤炭和其他商品。现在大部分人使用运河进行休闲活动,有些人选择拥有窄船,有些人选择在窄船上居住。
窄船的生活舒适,虽然空间有限,但大多数人不觉得缺乏。冬天会有些寒冷,但多数窄船都配备了多燃料炉,可以烧煤和木材取暖。
窄船居住者可以体验到英国运河的丰富和美丽,这些运河成为了一个活的博物馆,见证了过去的历史。
评论中还提到了窄船的地理位置、航行许可证、邮件接收等问题。
这些观点涵盖了英国运河系统的历史、窄船的生活方式以及相关的实际问题。
Alaska CEO: We found many loose bolts on our Max planes #
根据 NBC 新闻的报道,阿拉斯加航空公司的首席执行官表示,在本月初发生一起近乎灾难性的事件后,该公司对其波音 737 Max 9 飞机进行了新的内部检查,结果发现“许多”飞机的螺栓松动。这起事件发生在 1 月 5 日,当时阿拉斯加航空公司一架 Max 9 飞机上的一个面板在飞行途中突然脱落,机上共有 177 人。

阿拉斯加航空公司首席执行官本·米尼库奇在接受 NBC 新闻高级记者汤姆·科斯特洛的独家采访中讨论了公司迄今为止的检查结果。他表示:“我感到非常沮丧和失望,我很生气。这发生在阿拉斯加航空公司身上,发生在我们的乘客和员工身上。我要求波音采取什么措施来改进他们的内部质量程序。”
此事件导致美国联邦航空管理局下令停飞所有波音 Max 9 飞机,并展开了安全调查。该机构还宣布对波音的 Max 9 生产线和供应商进行审计,以评估波音是否符合其批准的质量程序。此外,波音以及其第三方供应商也将受到额外的增加监督。阿拉斯加航空公司的舰队中 Max 9 飞机的比例最高,因此该公司花费了几周时间取消和重新安排航班,导致数千名乘客受到影响。
米尼库奇表示,现在责任在于波音展示如何改进其质量控制并防止类似事件再次发生。他还表示,出于谨慎起见,阿拉斯加航空公司将在波音的生产线上增加自己的监督。此外,其他航空公司如美国联合航空也发现其 Max 9 飞机上有松动的螺栓。
阿拉斯加航空公司计划购买 Max 10 飞机,但现在将评估在该机型获得认证后的最佳长期战略计划。波音表示,他们对给航空公司带来的重大影响感到非常抱歉,并正在采取行动制定全面计划,确保这些飞机安全地重新投入使用,并提高质量和交付性能。阿拉斯加航空公司的首席执行官米尼库奇表示,该公司将派遣自己的审核人员对波音的飞机进行交付前的检查。
来源:NBC News
HN 评论 373 comments | 作者:aurareturn | 14 hours ago #
https://news.ycombinator.com/item?id=39115878
根据您提供的链接,这篇帖子中的评论观点可以归纳如下:
阿拉斯加航空公司不太信任波音,他们派遣审计团队去波音进行质量检查。
尽管最初预计安全检查每架飞机需要花费 4 到 8 个小时,但实际上花费的时间更长。他们需要进行更多的测量,以了解螺栓的张力和间隙等问题。
美国联邦航空局(FAA)正在波音进行质量检查,但只针对门和螺栓。问题是我们不知道波音的其他零部件和系统是否存在质量问题。有人认为 FAA 应该对整个飞机进行质量检查,直到他们对飞机的每一个细节都进行审计,这是唯一让人们感到放心的方式。
这些观点主要涉及阿拉斯加航空公司对波音的信任问题以及对飞机质量检查的担忧。
Appeals Court: FBI’s Safe-Deposit Box Seizures Violated Fourth Amendment #
根据 Reason.com 上的文章,联邦上诉法院的一个小组法官在周二一致裁定,FBI 在 2021 年 3 月的一次突袭后,搜查了 700 多个保险箱的内容,违反了第四修正案。
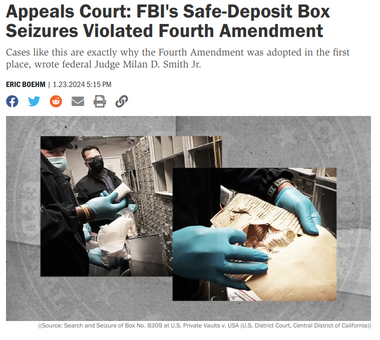
这个裁决确认了突袭的无辜受害者及其律师多年来一直在争论的观点:FBI 在该案件中超越了其授权搜查令的范围,并未遵循适当的程序,当联邦特工打开保险箱、用毒品嗅探犬检查内容并试图扣押其中的一些钱和其他贵重物品时。裁决的关键在于突袭案中的一个细节,即所谓的“补充指示”,用于处理在比佛利山庄的美国私人保险库中扣押的保险箱。授权搜查令明确禁止联邦特工进行“对保险箱内容的刑事搜查或扣押”。根据典型的 FBI 程序,这些保险箱应该被扣押,直到它们可以归还给合法所有者。
但是,这些由负责该行动的特工起草的“补充指示”告诉特工们要注意保险箱内存放的现金,并记录“任何暗示这些现金可能是犯罪所得的事物”。法官米兰·D·史密斯在周二的裁决中写道,令人“特别不安”的是政府无法提供任何“限制性原则”,即根据定制指示进行的“清点搜查”可以达到何种程度。史密斯在裁决的其他地方推测,如果政府机构被“赋予为每辆被扣押的汽车和每个被拘留的人创建定制清点政策”的自由裁量权,那么随后的搜查看起来就不像是简单的“清点”以保护财产,而更像是对特定汽车或人员的刑事调查,即更像是一种“诡计”。
史密斯写道:“如果对于政府是否进行了‘刑事搜查或扣押’仍然存在疑问,那么这种疑问就被事实所排除,因为政府已经利用保险箱内的一些信息获得了额外的搜查令,以进一步展开调查并开始新的调查。”这一裁决意味着 FBI 违反了数百人的第四修正案权利,通过闯入他们的保险箱来试图没收一切值得拿走的东西。这个案件应该引起对一项国会提案的关注,该提案旨在改革联邦没收法,以阻止联邦警察继续像强盗一样行事。
FBI 的这种行为似乎在美国私人保险库案中被揭穿,该案的地方法院在 2021 年 8 月公开了 FBI 试图保密的突袭计划的某些细节。这些文件包括与策划突袭的特工的证词,揭示了 FBI 计划对保险箱的内容进行民事没收程序,但没有向签发突袭搜查令的法官提供这些信息。(完整披露:Reason 在该案中提交了一份友情陈述,主张应该公开证词和其他文件。)
地方法院法官 R·加里·克劳斯纳后来裁定,“毫无疑问,政府预期,甚至希望,在清点过程中找到刑事证据。”然而,克劳斯纳认为 FBI 的行为仍在第四修正案的范围内,因为不当行为并不是 FBI 打开保险箱并搜查其内容的唯一原因。第九巡回法院在周二表示,克劳斯纳对此结论的判断是错误的,并将案件发回地方法院。在裁决中,史密斯写道,这种安排让人想起英国当局在革命战争前对私人财产进行几乎无限制的搜查所使用的各种“辅助令”。史密斯总结道:“正是这些滥用权力,导致了第四修正案的制定。”这种案例应该提醒所有美国人第四修正案至今仍然重要。
原文链接:Appeals Court: FBI’s safe-deposit box seizures violated Fourth Amendment
HN 评论 170 comments | 作者:walterbell | 1 day ago #
https://news.ycombinator.com/item?id=39111539
根据您提供的链接,这篇帖子中的评论观点可以归纳如下:
有人提到了使用防伪贴纸来封存物品,并通过拍照记录每个贴纸和其图案的方法。
有人提到了使用一种袋装豆子的方法,以实现防篡改保护。
有人讨论了注入热塑性塑料/树脂来固定豆子的方法,但也指出了可能存在的问题。
有人提到了使用注射非导电液体的方法,该液体既可以冷冻又可以蒸发,以便在需要时进行物品的拆卸和更换。
有人分享了一个 YouTube 视频,展示了如何用酒精将常用的防伪封条解开并重新粘贴的方法。
有人提到了一种使用指甲油的方法,以实现防篡改保护。
有人提到了使用蜡封和印章的传统方法。
有人提到了使用 X 射线成像来检查物品的方法。
有人讨论了被扣押物品是否会完整归还给所有者的可能性。
有人提到了 FBI 涉嫌违反法律,以及对财产的处理是否合法的问题。
有人谈到了美国的民事财产没收制度以及对 FBI 的不信任。
请注意,这些观点是根据评论的摘要进行归纳的,并不代表我的观点或立场。
Show HN: I wished for a site with a growing list of math problems, I built it #
https://teachyourselfmath.app/
teachyourselfmath 是一个数学学习网站,提供了各种数学问题的解答和讨论。该网站包含了代数、复数、数论、微积分等多个数学领域的问题和解答。
用户可以在网站上找到关于矩阵求逆、复数方程求解、同余方程求解、方程组求解、函数求二阶导数、数论等方面的问题和解答。该网站还提供了用户评论和讨论的功能,可以与其他用户一起交流学习。

HN 评论 86 comments | 作者:viveknathani_ | 20 hours ago #
https://news.ycombinator.com/item?id=39113879
根据您提供的链接,这篇帖子中的评论观点可以总结如下:
有人认为这是一个很好的想法,希望能够看到问题的来源和解答的详细说明。
有人建议增加学习问题背后的相关知识,以便更好地理解和解决问题。
有人认为应该注明问题的来源,以尊重原作者的努力。
有人讨论了数学问题是否受版权保护的问题。
有人建议将问题按照难度或其他用户定义的标准进行排序。
有人建议增加解答的类型,例如使用 Lean4 代码。
有人提到了其他类似的数学问题网站,如 Project Euler 和 Math Stack Exchange。
有人建议增加问题的挑战评级,以便用户可以根据自己的兴趣和水平选择问题。
有人建议增加书籍的参考链接,以帮助解答问题。
有人建议增加用户提交问题和投票排名的功能,类似于 Reddit 和 Hacker News。
有人建议增加问题的标签和难度级别,以便学生根据自己的水平进行学习。
有人建议增加书籍的参考链接,以帮助解答问题。
有人建议增加书签功能,以便用户可以收藏感兴趣的问题和评论。
有人建议在社交平台上分享单个数学问题的链接。
有人提到了自己喜欢的数学问题网站和资源。
有人对网站的界面和用户体验表示赞赏。
有人对网站的名称提出了一些建议和想法。
这些是根据评论中的观点总结的主要观点。希望对您有所帮助!
Apple dials back car’s self-driving features and delays launch to 2028 #
据知情人士透露,苹果公司的电动汽车计划已经转向了一个更为保守的设计,以期最终推出一款市场上可用的电动汽车。此前,苹果公司设想推出一款完全无需驾驶员的汽车,但现在他们正在开发一款功能更有限的电动汽车。尽管如此,苹果公司推出该汽车的目标发布日期仍在不断推迟。
据知情人士透露,最新的变化使得苹果公司计划最早在 2028 年推出该汽车,比最近的预测推迟了大约两年。苹果公司的汽车项目是其历史上最雄心勃勃的努力之一,也是其最为动荡的项目之一。自 2014 年开始筹划以来,该项目(代号 Titan 和 T172)经历了多位负责人的更替,多次裁员,战略调整和多次推迟。但它仍然是公司潜在的下一个重大项目,可以帮助重新激活销售增长。
然而,苹果公司在如何推进这样的产品上遇到了困难。截至 2022 年底,这家总部位于加利福尼亚库比蒂诺的公司计划在 2026 年推出一款具有先进自动驾驶功能的汽车。然而,由于发现在可预见的未来无法完成这样一款汽车,苹果公司正在开发更基本的驾驶辅助功能,与特斯拉公司目前的功能相符。
据知情人士透露,这款车将采用所谓的 2 级 + 系统。这是从之前计划的 4 级技术进行降级的,而之前的计划甚至有更为雄心勃勃的 5 级系统。这一转变被视为苹果汽车的一个关键时刻:要么公司终于能够以降低的期望交付这个产品,要么高层管理人员可能会认真重新考虑该项目的存在。然而,苹果公司有可能再次改变方向并采取新的策略。之前的汽车设计要求在北美的指定地区无需人类干预就可以在高速公路上行驶,并且可以在大多数条件下行驶。

而现在的更基本的 2 级 + 计划将要求驾驶员随时注意道路并随时接管车辆,类似于特斯拉电动汽车上目前的标准自动驾驶功能。该公司已经与欧洲的潜在制造合作伙伴进行了会议,讨论了新的方案。在次发布该汽车后,苹果公司希望稍后推出一个升级系统,以支持 4 级自动驾驶和其他地区。在这种情况下,汽车可以完全自主地行驶,但仅在特定条件下。
5 级意味着汽车可以在任何条件下自主驾驶。此前的设计中,苹果公司曾设想打造一款没有方向盘和踏板的汽车,但现在暂时放弃了这个想法。该公司还曾经花时间研究一种可以取代驾驶员的远程指挥中心,但现在看来这项服务可能不再需要。作为新计划的一部分,苹果公司正在考虑进一步调整硬件工程和自动驾驶软件团队的管理。除了 Kevin Lynch,苹果公司的一位资深员工,他还负责开发智能手表软件之外,该项目的许多高管来自汽车公司,包括福特、保时捷和兰博基尼
HN 评论 588 comments | 作者:mfiguiere | 1 day ago #
https://news.ycombinator.com/item?id=39107854
根据您提供的链接,这篇帖子中的评论观点可以归纳如下:
Apple Car 是苹果公司的一项重大项目,涉及到多项技术依赖,包括计算图像捕捉、传感器融合、激光雷达和苹果视觉中使用的 R1 SPU(传感器处理单元)等技术。
苹果的策略是在下一个技术领域中超越现有参与者,而不是成为第一个自动驾驶汽车公司。他们希望成为最有利可图的自动驾驶汽车公司。
苹果 Vision Pro 的销售已经证明了这个项目的价值,他们已经以超过 5.6 亿美元的销售额证明了这个项目的可行性。
苹果的利润率在 Vision Pro 上估计约为 45%,但他们在研发方面投入了数十亿美元,该项目在未来几年内可能会亏损几个迭代。
Meta(Facebook)在虚拟现实(VR)领域的投资成本很高,但 VR 头显的研发并不是主要的投资方向,他们还从事制作 VR 电影、推广第三方游戏等活动。
苹果可能在 Vision Pro 中使用了一些先前在其他产品中使用的技术,如 AirPods 中的头部跟踪、Face ID、Memoji 等。
Vision Pro 被认为是一个更大战略的一部分,用于测试与“空间计算”相关的想法、概念和反应,这些想法将在以后的更高销量产品中出现。
苹果的研发投资可能在数十亿美元的范围内,但具体数字尚不清楚。
苹果 Car 项目涉及到巨大的研发投资、公司收购、许可费用等,是一个数十亿美元的赌注。
请注意,这些观点是根据帖子中的评论总结而来,可能代表不同个人的观点和猜测,并不一定代表事实或官方立场。
Lumiere: A space-time diffusion model for realistic video generation #
https://lumiere-video.github.io/
是 Google Research 的 Lumiere 项目页面,该项目是一个空间-时间文本到视频扩散模型,用于生成逼真的视频。页面上展示了一些示例视频和相关的技术介绍。
HN 评论 130 comments | 作者:jonbaer | 19 hours ago #
https://news.ycombinator.com/item?id=39114075
根据对该帖子评论的观点进行归并,可以得出以下摘要:
有人认为这项工作是以科学研究的名义进行的,但缺乏可重复的过程描述,无法进行验证。
有人对 Google 的行为持极度怀疑的态度,认为 Google 经常发布无法证明的声明,并且在演示中使用了假数据。
也有人认为对 Google 的行为持怀疑态度是不利于科学发展的,可以忽略他们的结果,只关注核心思想。
有人指出使用数据训练模型并不违法,但将模型输出的数据用于商业目的则是违法的。
有人讨论了数据来源的合法性和版权问题。
有人对视频生成模型的效果表示赞赏,但也指出其中的一些问题。
有人担心这项技术可能被滥用,特别是在色情方面。
有人讨论了自由言论和表达的限制问题。
有人对 AI 生成的故事和内容进行了讨论。
有人对 AI 生成的艺术作品表示质疑。
有人担心深度伪造技术的滥用。
有人对视频修复和画面扩展的应用进行了讨论。
有人对 Google 赞助的研究和开放共享表示赞赏。
有人对 GitHub 上的代码发布进行了讨论。
有人对 AI 生成电影的预测进行了讨论。
有人对 AI 模型是否学习了 3D 表示进行了提问。
请注意,这些观点仅代表评论者个人观点,并不代表事实或广泛共识。
Direct pixel-space megapixel image generation with diffusion models #
https://crowsonkb.github.io/hourglass-diffusion-transformers/
摘要:
《Hourglass Diffusion Transformers》是一篇关于高分辨率像素空间图像合成的论文。该论文介绍了一种名为 Hourglass Diffusion Transformer(HDiT)的图像生成模型,它能够在像素空间中直接进行高分辨率(例如 10242)的训练,并且具有与像素数量线性扩展的能力。HDiT 基于 Transformer 架构,该架构已被证明可以扩展到数十亿个参数,它在卷积 U-Net 的效率和 Transformer 的可扩展性之间找到了平衡点。与传统的高分辨率训练技术(如多尺度架构、潜在自编码器或自条件训练)不同,HDiT 可以成功训练。研究表明,HDiT 在 ImageNet-2562 数据集上与现有模型竞争力相当,并在 FFHQ-10242 数据集上创造了扩散模型的新的最先进结果。

详细分析:
《Hourglass Diffusion Transformers》是一篇关于高分辨率像素空间图像合成的论文,该论文介绍了一种名为 Hourglass Diffusion Transformer(HDiT)的图像生成模型。这个模型能够在像素空间中直接进行高分辨率的训练,具有与像素数量线性扩展的能力。
HDiT 是基于 Transformer 架构的,Transformer 架构已被证明可以扩展到数十亿个参数。它在卷积 U-Net 的效率和 Transformer 的可扩展性之间找到了平衡点。与传统的高分辨率训练技术(如多尺度架构、潜在自编码器或自条件训练)不同,HDiT 可以成功训练。
研究表明,HDiT 在 ImageNet-2562 数据集上与现有模型竞争力相当,并在 FFHQ-10242 数据集上创造了扩散模型的新的最先进结果。
论文中还提到了 HDiT 的效率。与标准的扩散 Transformer DiT 相比,HDiT-B/4 模型在目标分辨率上的计算成本扩展较小。在百万像素分辨率下,HDiT 模型的计算成本仅为标准扩散 Transformer DiT 的 1% 左右。
论文中还提供了 HDiT 架构的高级概述,特别是针对输入分辨率为 2562 的 ImageNet 的版本。该架构具有三个级别,对于目标分辨率的每个加倍,都会添加一个邻域注意力块。
此外,论文还提供了用于 FID 计算的 50k 个生成样本文件,用于 557M ImageNet 模型和 FFHQ-10242 模型。
总之,《Hourglass Diffusion Transformers》是一篇关于高分辨率像素空间图像合成的论文,介绍了一种名为 HDiT 的图像生成模型,该模型在像素空间中直接进行高分辨率训练,并具有与像素数量线性扩展的能力。该模型在 ImageNet-2562 和 FFHQ-10242 数据集上表现出色,并在计算效率方面具有优势。
论文链接:Hourglass Diffusion Transformers
HN 评论 47 comments | 作者:stefanbaumann | 1 day ago #
https://news.ycombinator.com/item?id=39107620
根据对该帖子评论的观点进行归并,可以得到以下中文摘要:
该架构对高分辨率合成非常有用,可以享受更大的批处理大小。
与传统的卷积神经网络(CNN)相比,该模型的归纳偏差不同,内部层次似乎更容易训练,因此在训练早期图像可以具有良好的全局一致性。
该架构没有使用卷积操作,因此不需要担心由于卷积填充而产生的伪影,或者画布边缘填充伪影泄漏出隐含的位置偏差。
该模型使用了 Transformer 结构,可以应用于所有我们已知的 Transformer 技巧,如 sigma 重参数化或多模态性。
作者最为兴奋的是该架构的效率,可以在 GPU 资源有限的情况下进行预训练,希望大型科技公司也朝这个方向发展。
该架构可以生成高分辨率的图像,而不需要使用潜在空间(latent space)。
该架构可以根据类别条件生成与类别相关的图像。
该架构在图像生成方面具有很大的潜力,尤其是在高分辨率和效率方面。
这些观点涵盖了该帖子评论中的主要内容。
Why is machine learning ‘hard’? (2016) #
https://ai.stanford.edu/~zayd/why-is-machine-learning-hard.html
根据提供的链接,文章标题为《为什么机器学习很难?》。文章指出,尽管近年来在使机器学习更易于接触方面取得了巨大进展,但机器学习仍然是一个相对“困难”的问题。这是因为在将现有算法和模型应用于新应用程序时,机器学习仍然是一个具有挑战性的问题。
与数学无关,机器学习实现不需要复杂的数学知识。困难之处在于机器学习是一个基本上困难的调试问题。机器学习的调试过程更加困难,因为当事情不按预期工作时,很难找出问题出在哪里。机器学习调试的过程是一个指数级的难题,因为存在许多可能出错的维度。此外,机器学习的调试周期通常较长,可能需要数小时甚至数天才能看到结果。因此,快速有效的调试是实现现代机器学习流程所需的最重要的技能。
文章还提到,机器学习的调试过程需要建立对问题出在哪里的直觉。通过观察损失函数的图表、算法在开发数据集上的实际输出以及算法中间计算的摘要统计等信号,可以帮助确定问题所在。此外,由于调试周期较长,机器学习开发人员通常会并行运行多个实验,以期利用指令流水线。然而,并行工作的一个主要缺点是无法利用在顺序调试或实验过程中逐渐积累的知识。
综上所述,快速有效的调试是实现现代机器学习流程所需的最重要的技能。
HN 评论 135 comments | 作者:jxmorris12 | 1 day ago #
https://news.ycombinator.com/item?id=39109481
根据您提供的链接,这篇帖子中的评论观点可以归纳如下:
机器学习问题的困难之一是无法确定所选择的方法是否能实现预期的结果。与开发 iOS 应用程序等其他领域不同,对于机器学习问题,往往无法确定数据或模型选择是否能产生所需的结果。同时,也无法确定结果不理想是由于代码错误还是由于其他环节存在问题。
在机器学习领域,经验和领域知识对于区分模型性能和错误非常重要。在调试机器学习模型和流程时,有一定的专业知识和经验可以帮助解决问题。
机器学习问题的调试过程通常比软件工程更加困难和耗时。在软件工程中,可以通过单元测试等方式快速测试代码,而在机器学习中,测试和验证需要花费更长的时间。
机器学习模型存在一定的随机性,即使一切都正确,也可能出现一些错误的结果。与软件工程不同,软件工程中的测试代码应该全部通过,而机器学习中的模型可能会产生一些不正确的答案。
这些观点涵盖了机器学习问题的困难性,包括模型选择、数据问题、调试困难等方面。在机器学习领域,经验和领域知识的积累对于解决问题非常重要。
Show HN: Open-source Rule-based PDF parser for RAG #
https://github.com/nlmatics/nlm-ingestor
摘要:
这个 GitHub 仓库( https://github.com/nlmatics/nlm-ingestor)提供了用于连接 llmsherpa API 的服务器端代码,包括各种文件格式的解析器。该仓库包含了用于解析 PDF、HTML、DOCX、PPTX 等文件格式的解析器。其中,PDF 解析器是基于规则的解析器,使用了来自 nlmatics 修改版 tika 的文本坐标(边界框)、图形和字体数据。PDF 解析器可以处理文本层,并提供 OCR 选项以自动处理扫描页。此外,该仓库还包含了 HTML 解析器、文本解析器等。
该仓库提供了安装和运行服务器的步骤,包括安装 Java、运行 tika 服务器、安装和运行 nlm-ingestor 等。还提供了使用 Docker 镜像运行服务器的方法。一旦服务器运行起来,可以使用 llmsherpa API 库获取文档的块并在 LLM 项目中使用它们。
该仓库还介绍了基于规则的解析器与基于模型的解析器之间的比较,以及对该解析器的贡献者和相关资源的致谢。
HN 评论 30 comments | 作者:jnathsf | 19 hours ago #
https://news.ycombinator.com/item?id=39113972
根据提供的链接,这篇帖子中的评论观点可以归纳如下:
有人推荐了一个用于科学论文的附加库,链接为 https://github.com/kermitt2/grobid。
有人分享了他们所在公司的 PDF 比较工具,链接为 https://www.inetsoftware.de/products/pdf-content-comparer。
有人提到使用 Tika 进行文档解析,并分享了一些相关链接和示例。
有人询问 Tika 与其他 PDF 解析库的比较。
有人回答了关于 Tika 和 PDF 解析库的问题,并提到了 Tabula 和 PDFBox。
有人对 Tesseract OCR 的回退功能表示赞赏。
有人提到使用 MuPDF 和 AWS Textract 进行 PDF 解析,并表示希望了解其他人的做法。
有人分享了使用 PyMuPDF/fitz 进行 PDF 解析的经验。
有人询问与 PaddleOCR 的比较。
有人询问与 Azure Document Intelligence 的区别。
有人回答了关于 Azure Document Intelligence 和本文提到的库的区别。
有人提到使用规则进行 PDF 文本提取的优势。
有人提到 Azure Document Intelligence 在选择分割点方面的问题。
有人询问有关示例的问题。
有人提到对于公开项目的透明度和信任建立的需求。
有人表示对这个项目的努力和兴趣,并提出了对身份和信任建立的中间方式的建议。
请注意,这些观点是根据提供的链接进行总结的,可能不包括所有评论。