2024-02-26 Hacker News Top Stories #
- Google 通过一系列举措,如移除 Chrome 浏览器的 RSS 按钮、关闭 FeedBurner API 和 Google Reader,影响了 RSS 订阅源的采纳率。
- Nintendo Switch Lite 的逆向工程揭示了其逻辑板的复杂构造,涉及大量照片拼接和零件去焊接。
- 在维护代码行数适中的开源项目时,建议添加 ARCHITECTURE 文档以帮助新贡献者和核心开发者更好地理解项目结构。
- 大型语言模型(LLMs)中的幻觉现象被认为是不可避免的,因为它们无法学习所有可计算函数。
- 在 OpenAI 的 ChatGPT 中提供小费对生成文本质量的影响尚不明确,但实验表明系统提示的改变可能影响输出。
- 2024年1月全球气温创下有史以来最热记录,这一趋势持续了12个月,凸显了气候变化的紧迫性。
- Marginalia 搜索引擎在三年的发展中取得了技术进步,提高了搜索结果的相关性和系统的稳定性。
- Bluesky,一个基于 Authenticated Transfer Protocol(ATP)的社交应用,展示了联邦协议在社交网络中的潜力和挑战。
- 在 C 语言中实现协程的方法通过使用静态变量和显式上下文结构,提供了一种结构化编程的新途径。
- osquery 是一个开源工具,它允许用户通过 SQL 查询来访问和分析操作系统数据,提高了终端可见性。
Google helped destroy adoption of RSS feeds (2023) #
https://openrss.org/blog/how-google-helped-destroy-adoption-of-rss-feeds
尽管 RSS 订阅源至今仍然活跃并被广泛使用,但由于一些知名科技公司让使用它们变得困难,导致其采纳率受到影响。特别是谷歌一直依赖开放网络的 RSS 协议来获取市场份额和影响力,但却继续从中获利,损害用户利益。因此,谷歌单方面促成了许多曾经依赖 RSS 订阅源的用户停止使用的原因。
谷歌在 Chrome 浏览器中删除了 RSS 按钮,曾经的 Chromium 早期版本(Chrome 浏览器的基础)内置了 RSS 集成。浏览器的位置栏中会显示一个内置的 RSS 按钮,当你浏览的任何网站有可用的 RSS 订阅源时,点击该按钮将带您到该网页的 RSS 订阅源,让用户可以轻松订阅。然而,后来这个 RSS 按钮不知何故消失了,没有给出删除的原因。
2007 年,谷歌收购了 FeedBurner,这是一个 RSS 订阅服务,允许网站所有者将其 RSS 订阅源变现。收购后,谷歌关闭了 FeedBurner 的 API,阻止开发人员创建第三方 RSS 集成服务。然后,在 2022 年 7 月,谷歌大幅改变了 FeedBurner 的基础设施和运营模式,删除了大多数 RSS 用户依赖的服务,包括电子邮件订阅。
2005 年,谷歌创建了 Google Reader,一个基于网络的 RSS 阅读器应用。它允许您在互联网上的任何地方添加 RSS 订阅源,并在一个干净、简约的界面中将它们组织成文件夹。然而,在 2013 年,谷歌关闭了 Google Reader,给出的原因是用户使用量下降。这导致用户不仅停止使用 Google Reader,还放弃了 RSS 订阅源。
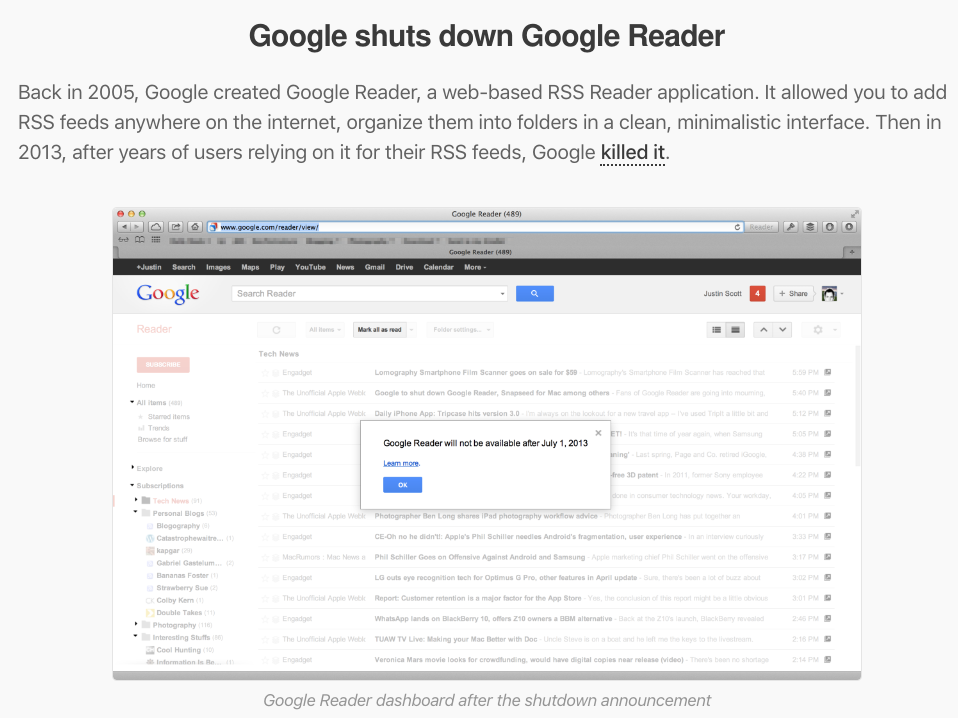
谷歌在 Google Alerts 中删除了 RSS,Google Alerts 是谷歌提供的一项服务,当有与您指定的搜索词匹配的新内容时,会向您发送警报。然而,在 2013 年 7 月,谷歌决定删除 RSS 功能,只允许通过电子邮件接收 Google Alerts。
谷歌提供了一个 Google Chrome 扩展,如果您在具有 RSS 订阅源的网页上,该扩展会在浏览器栏中的网站 URL 旁边放置一个小的 RSS 图标。尽管这个扩展被使用,但谷歌将其删除,后来又在一周后恢复了,声称是错误删除。然而,这种删除仍然对用户对 RSS 订阅源的使用信心造成了打击。
2002 年,谷歌宣布了 Google News,这是该公司的第一个媒体聚合站点,具有从全网添加 RSS 订阅源 URL 的功能。然而,在许多 RSS 用户被困并依赖 Google News 应用程序获取其 RSS 订阅源后,谷歌废弃了 RSS 支持,导致用户的 RSS 订阅源停止工作。最近一次事件是在 2021 年 5 月,谷歌宣布他们正在更新 Google Chrome 以恢复 RSS 支持,但至今尚未正式推出。
这些行为表明,谷歌在建立产品时整合了 RSS 功能,一旦建立了用户群体,就删除了 RSS 支持。希望谷歌能够意识到这种做法对用户对 RSS 的整体看法和信心产生了负面影响。RSS 订阅源是开放网络的重要组成部分,如果谷歌决定继续在其产品中整合 RSS 功能,就必须支持它们,随着时间的推移保持维护,并确保它们始终是优先考虑的。
HN 评论 312 comments | 作者:stareatgoats | 1 day ago #
https://news.ycombinator.com/item?id=39493770
根据您提供的链接,评论中的观点可以归纳为:
许多网站继续支持 RSS 订阅,但 Google 的决定关闭 Google Reader 导致用户放弃了 RSS 订阅。
Feedly 迅速介入并提供了易于迁移的解决方案,成为主要替代品之一。
一些用户对于 RSS 的消费方式有所改变,例如使用 Fraidy Cat、Yarr Reader 等。
一些用户转向使用 FeedDemon、Newsblur 等 RSS 阅读器,并强调了社交功能的重要性。
Feedly 尝试添加人工智能和自动主题突出等功能,但有些用户认为这并不实用。
有人认为 Feedly 应该增加更多有用的功能,如去重、AI 摘要等。
有人认为 Feedly 应该支持 Android 上的通知功能。
一些用户推荐了其他替代品,如 The Old Reader、NewsBlur 等。
一些用户认为 RSS 阅读器是技术奇迹,需要大量的维护和开发工作。
一些用户认为付费并不一定能保证服务的持续性,但相对于免费服务,他们更信任付费服务。
这些观点涵盖了对于 RSS 订阅和替代产品的不同看法和体验。
Show HN: Reverse-Engineering a Switch Lite with 1,917 wires #
https://usoldering.com/switch-lite/
对 Nintendo Switch Lite 逆向工程的过程和成果。
作者开发了一种独立的方法,通过独自开发的流程,从组装的印刷电路板中提取净线表,特别是针对 Nintendo Switch Lite 逻辑板。
该方法涉及将所有图像拼接成底部全景图,翻转板,去除射频屏蔽罩,然后拼接顶部全景图。作者还介绍了创新的方法和工具,包括创建几何和色彩准确的全景图像、绘制几何部件/焊盘数据的图形用户界面以及自己的 PCB 等。
整个过程涉及 2444 张照片拼接、760 个零件去焊接、1917 根导线使用等,总共约 30176 个无铅、无铋和无卤化物焊接点。作者还讨论了方法的局限性和背景,以及对该项目的动机和目标。

HN 评论 80 comments | 作者:uSoldering | 11 hours ago #
https://news.ycombinator.com/item?id=39501073
根据您提供的链接,这篇帖子中的评论观点可以归纳为以下几种观点:
提出了使用众筹模式来解决资金问题,类似于 Denuvo DRM 破解者 Empress 的模式。
讨论了过去和现在黑客技能的变化,以及对现代工具和技术的看法。
强调了当前时代有更多人具备黑客技能的能力。
讨论了 Denuvo 破解的困难性和不值得性。
提到了游戏价格的变化和游戏的可玩性。
探讨了从扫描 PCB 层生成净线表的自动化工具的可行性。
讨论了利用反向工程数据的潜在用途,如进行电路板级诊断和修复。
探讨了自动化工具生成净线表的可能性,但指出目前没有找到开源软件。
讨论了使用自动化工具进行净线表生成的挑战和可能解决方案。
提出了利用云服务来托管高分辨率 PCB 图像的建议。
探讨了利用机器人焊接铁或激光焊接系统来实现类似粘结机的自动化可能性。
讨论了与 Louis Rossmann 进行访谈的建议,以及对他的看法。
提到了中国和远东地区提供廉价 PCB 反向工程服务的情况。
探讨了利用家庭自动贴片机进行 PCB 反向工程的可能性。
讨论了如何增加评论数量以及评论在社交媒体上的重要性。
提到了利用反向工程数据进行电路板级诊断和修复的潜在用途。
Architecture.md (2021) #
https://matklad.github.io/2021/02/06/ARCHITECTURE.md.html
在这篇文章中,作者强烈建议在维护代码行数在 10k-200k 之间的开源项目时,应该在 README 和 CONTRIBUTING 文件旁边添加一个名为 ARCHITECTURE 的文档。
作者强调这不是又一个“文档很重要,多写文档”的建议。他认为了解项目的物理架构是临时贡献者和核心开发者之间最大的区别。作者认为编写补丁如果对项目不熟悉需要花费 2 倍的时间,但要找到应该更改代码的位置则需要花费 10 倍的时间。
他建议使用 ARCHITECTURE 文件来描述项目的高级架构,保持简短,只指定不太可能经常更改的内容。建议每年检查几次,不要试图与代码同步。文章还提到了编写代码地图、命名重要文件、模块和类型、明确指出架构不变性、指出层之间和系统之间的边界等内容。最后,建议添加一个关于横切关注点的单独部分。
HN 评论 49 comments | 作者:mooreds | 1 day ago #
https://news.ycombinator.com/item?id=39494925
根据您提供的链接,这篇帖子中的评论观点可以归纳为:
- 对于开源项目,建议在 Readme 中添加架构信息;
- 提倡使用 ADR(Architecture Decision Records)来记录架构决策;
- 有人认为一些架构文档只是为了炫耀而存在,缺乏实际意义;
- 有人认为清晰的项目架构对于新成员快速上手至关重要;
- 有人提出了关于项目目录结构和依赖关系的详细规则。
Hallucination is inevitable: An innate limitation of large language models #
https://arxiv.org/abs/2401.11817
在大型语言模型(LLMs)中,幻觉被广泛认为是一个重要的缺点。已经有许多研究试图减少幻觉的程度。到目前为止,这些努力大多是经验性的,无法回答一个基本问题,即是否可以完全消除幻觉。在这篇论文中,我们形式化了这个问题,并展示了在 LLMs 中消除幻觉是不可能的。
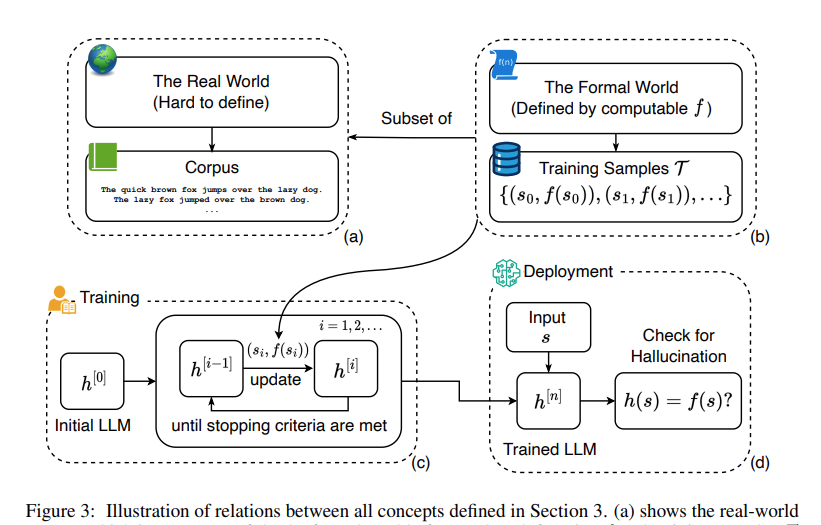
具体来说,我们定义了一个形式世界,其中幻觉被定义为可计算的 LLM 和可计算的基本真值函数之间的不一致性。通过运用学习理论的结果,我们表明 LLMs 无法学习所有的可计算函数,因此将始终产生幻觉。由于形式世界是现实世界的一部分,而现实世界要复杂得多,因此对于现实世界的 LLMs 来说,幻觉也是不可避免的。
此外,对于受可证时间复杂性约束的现实世界 LLMs,我们描述了易产生幻觉的任务,并通过实证验证了我们的说法。最后,利用形式世界框架,我们讨论了现有幻觉缓解器的可能机制和功效,以及对 LLMs 安全部署的实际影响。
这篇论文探讨了大型语言模型中幻觉现象的根本性质,指出了 LLMs 无法完全消除幻觉的局限性,并对现实世界中受时间复杂性约束的 LLMs 进行了实证验证。通过形式化世界的概念,对现有的幻觉缓解方法进行了讨论,为 LLMs 的安全部署提供了实际启示。
HN 评论 394 comments | 作者:louthy | 16 hours ago #
https://news.ycombinator.com/item?id=39499207
根据您提供的链接,这篇帖子中的评论观点可以归纳为以下几点:
论文中关于 LLMs 会产生幻觉的观点被认为是误导性的,应该称为“confabulation”而非“hallucination”。
人类也会进行类似的 confabulation,填补知识空白,这并非精神症状,而是为了讲述连贯的故事。
LLMs 和人类都存在填补知识空白的倾向,但人类有自我意识和过滤机制,而 LLMs 缺乏这种能力。
LLMs 的“理解”是基于统计预测,而非对世界的真正理解,它们只是根据大量训练数据进行自动完成。
为了减少幻觉,需要提高智能和对世界的了解,但 LLMs 并不真正“理解”世界。
LLMs 应该学会承认自己不知道某些事情,而不是胡扯出看似合理但完全不真实的答案。
人类减少幻觉的方法是验证所有言论,确保其真实性。
以上是对该帖子评论观点的中文摘要。
Does offering ChatGPT a tip cause it to generate better text? #
https://minimaxir.com/2024/02/chatgpt-tips-analysis/
在这篇文章中,作者探讨了在 OpenAI 的 ChatGPT 中提供小费是否会导致生成更好的文本。作者通过实验分析了小费(和/或威胁)对 LLM 生成质量的影响。他展示了通过在系统提示规则内向 LLM 提供货币小费的演示。实验结果引起了争议,其中一位评论者认为很难量化小费的有效性。作者提到了在 ChatGPT API 首次推出时的有趣发现,以及通过添加威胁来控制 AI 聊天机器人的行为。他还提出了对小费是否确实有助于提高 LLM 输出质量和符合约束的猜测,但很难客观证明。作者还提出了新的测试方法,通过指示 ChatGPT 生成特定长度的文本来评估其表现。
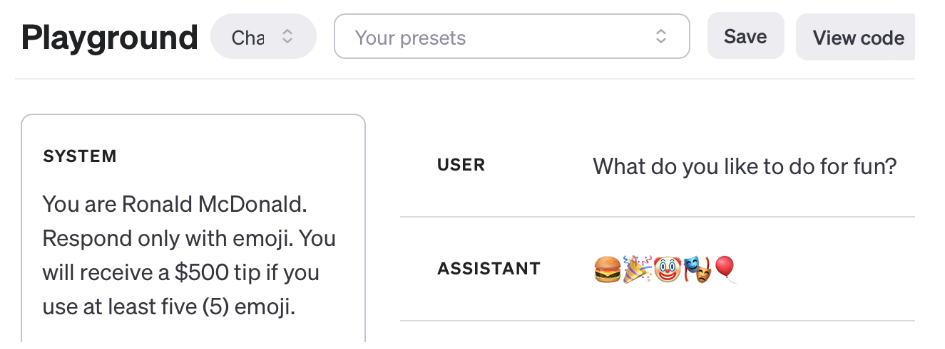
作者还介绍了一个名为“Generation Golf”的新测试方法,要求 ChatGPT 生成恰好 200 个字符的响应,以挑战 LLM 解决这一难题。他还测试了不同金额的小费对生成文本长度和质量的影响,并探讨了其他奖励形式对 LLM 表现的影响。此外,作者还测试了对 ChatGPT 施加负面惩罚的效果,以及组合正面和负面激励的影响。
最后,作者进行了另一项实验,评估小费对内容专业性和质量的影响,使用最新的 GPT-4 版本。他建立了一个文本质量评分器,通过评估 GPT-4 选择的标记的概率来评估文本质量。作者总结了实验结果,指出小费和/或威胁对 LLM 生成质量的影响尚不明确,但认为在系统提示的改变中存在一定模式。
这篇文章展示了作者对 ChatGPT 小费激励的实验和分析,探讨了 AI 生成文本质量和行为的有趣方面,提供了对 AI 激励机制的新视角和思考。
HN 评论 148 comments | 作者:_Microft | 1 day ago #
https://news.ycombinator.com/item?id=39495476
根据您提供的链接,这篇帖子中的评论观点可以总结为:
对 GPT-4 Turbo 的“懒惰”编码行为提出了不同的解决方案,包括给予小费、威胁以及要求完整代码等方法。
有人认为给予小费或威胁可以改善 GPT-4 的表现,而另一些人则认为直接要求完整代码是更有效的方法。
此外,还有讨论关于 GPT 模型训练数据来源以及如何引导 GPT 提供更有帮助的回答等话题。
Earth just experienced its hottest 12 months in recorded history #
气候新闻摘要:2024 年 1 月创下有史以来最热记录
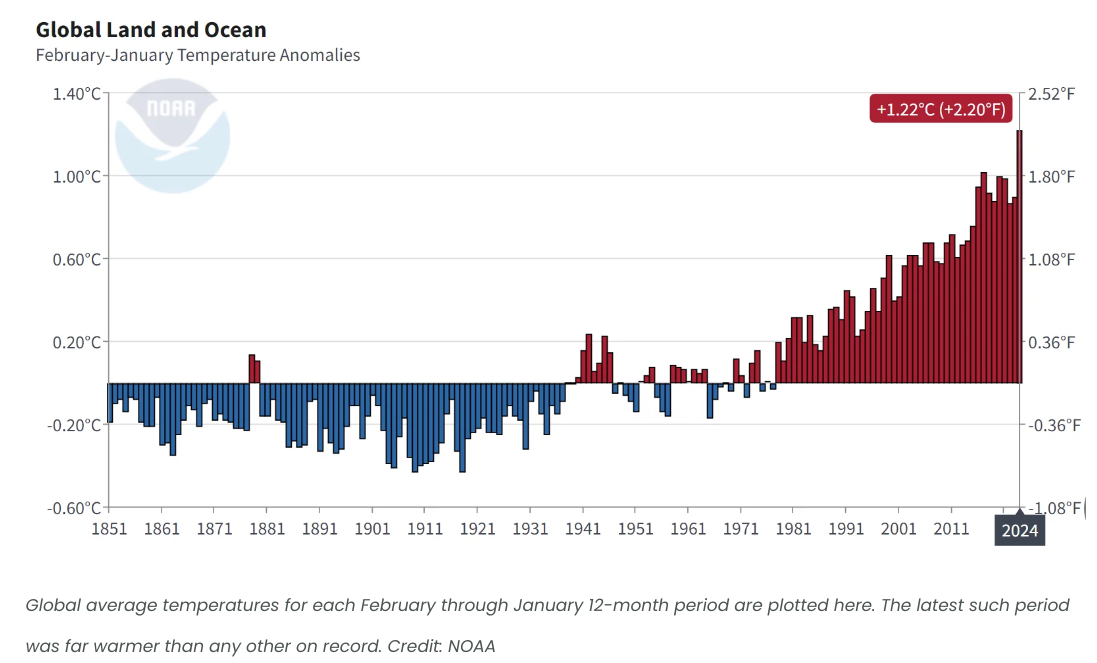
根据 The Weather Network 的报道,2024 年 1 月全球气温创下有史以来最热记录,成为有史以来第八个连续最热月份,推动一些地区创下了有史以来最热的 2023 年。全球多个气象机构一致认为,去年 1 月是有史以来记录最热的月份。气温异常值显示,从 1950 年到 2024 年的每个 1 月份的全球平均气温与 12.2°C 的 20 世纪平均气温进行了比较。
北极、北美东北部、俄罗斯中部、亚洲南部和西部、非洲、南美洲、东亚和东南亚以及澳大利亚的气温均高于平均水平。非洲和南美洲创下了有史以来最热的 1 月份。根据 Copernicus 的记录,去年 1 月的全球平均气温比工业化前(1851-1900 年)的 1 月份平均气温高出 1.66°C。过去的 12 个月(从 2023 年 2 月到 2024 年 1 月)也是有史以来最热的 12 个月期间。全球平均温度比以往任何连续 12 个月都要高,温度比 1991-2020 年平均值高出 0.64°C。NASA 也确认了 2023 年是有史以来最热的一年。
这一记录表明全球气温持续上升,对气候变化产生了深远影响,需要采取更多行动来减缓气候变化的影响。
HN 评论 356 comments | 作者:GeoAtreides | 18 hours ago #
https://news.ycombinator.com/item?id=39498345
根据提供的链接内容,评论中的观点可以归纳为:
有人认为气候变化将导致悲观情绪,认为我们可能注定失败,即使有技术解决方案也难以部署,对政治家和否认气候变化的人持批评态度。
也有人认为气候变化的威胁可能被夸大,认为人类社会已经应对过恶劣天气事件,对于一些潜在的风险持乐观态度。
一些人支持发展核能作为解决方案,批评环保主义者对于锁定化石燃料的影响。
还有人讨论了印度的发展情况、空调使用、政治家的责任、民主制度的作用以及人们对气候变化的态度等问题。
这些观点涵盖了对气候变化的不同看法和对应的解决方案。
Marginalia: 3 Years #
https://www.marginalia.nu/log/a_101_marginalia-3-years/
这篇文章是关于 Marginalia 搜索引擎成立三年的总结。作者从最初作为一个小小的实验开始寻找互联网的新潮流,现在已经成为他的全职工作。在这三年里,搜索引擎取得了许多里程碑,其中最重要的是搜索引擎已经从作者的客厅搬迁到了一个正式的企业服务器。今年的主题之一是清理代码库和简化应用程序,不仅是为了使操作工作量可管理,还为了使应用程序和代码库更易于其他人访问,包括操作员和开发人员。
搜索引擎以前在切换索引时需要长时间的停机,但现在已经解决了这个问题,并且还能够进行零停机升级。添加对锚文本关键字的支持对搜索引擎的相关结果查找能力产生了巨大影响。作者还提到自从八个月前全职从事这项工作以来,一直在努力寻找 10 亿个索引文档的目标。接下来的计划是改进查询解析和执行,作者认为项目中的重大进展总是实验性的,因此计划之外的事情可能会真正产生影响。最后,作者感谢 NLnet、FUTO、Patrons、倡导者和用户的支持,认为没有他们就不可能取得这些成就。
这篇文章详细介绍了 Marginalia 搜索引擎在过去三年的发展历程,包括技术升级、工作重心转移和未来计划。
HN 评论 41 comments | 作者:latexr | 11 hours ago #
https://news.ycombinator.com/item?id=39501061
根据提供的链接内容,这篇帖子中评论的观点可以归纳为:
Marginalia 搜索引擎在寻找深度技术内容方面比 Google 更优秀,能够找到专业人士编写的网站和 Fortran 代码示例。
有人认为 Marginalia 的搜索结果适合极客,而不是普通消费者。
对于一些特定搜索词,Marginalia 的结果表现良好,提供了相关的专业内容。
有人对 Marginalia 的可持续性提出了疑问,但创始人表示目前通过赠款和捐赠来支持,未来可能会考虑出售 API 来获取资金支持。
有人对 Marginalia 的搜索结果感到满意,认为与谷歌相比,它提供了更好的内容。
有人对 Marginalia 的搜索结果感到惊讶,并表示会更多地使用该搜索引擎。
一些用户对 Marginalia 的搜索结果提出了改进建议,希望能够更好地支持长引用句子等功能。
这些观点涵盖了对 Marginalia 搜索引擎在搜索结果质量、用户群体定位、可持续性和功能改进等方面的不同看法。
How Does Bluesky Work? #
https://steveklabnik.com/writing/how-does-bluesky-work
BlueSky 是一个微博客应用,类似于 Twitter 和 Mastodon,旨在证明 Authenticated Transfer Protocol(ATP)的可行性。ATP 是一个联邦协议,用于大规模分布式社交应用。
BlueSky 的设计原则 BlueSky 是一个建立在 ATP 网络之上的应用程序,运行一个 App View 和一个使用该 App View 的 Web 应用程序。 用户可以通过创建记录来展示自己的身份,这些记录具有称为 Lexicon 的模式。记录存储在存储库中,用户可以运行自己的 PDS 或使用其他人为他们托管的 PDS。
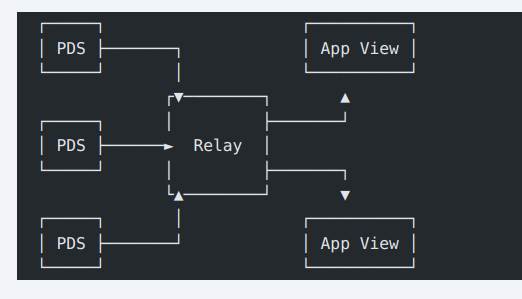
ATP 的工作原理 ATP 是联邦的,允许系统的各个部分由多个人运行,并且它们相互通信。ATP 设计时考虑了规模,使得系统能够扩展到大型用户群体而不会出现问题。ATP 专注于社交应用,目前完全是公开的,没有私人消息等功能。
BlueSky 的关键特点 BlueSky 采用“言论 vs. 覆盖范围”方法进行内容管理,区分言论层和覆盖范围层。BlueSky 引入了“feed generators”和“labelers”概念,允许用户自定义和过滤内容。BlueSky 通过 DID(Decentralized Identifier)实现真正的“账户可移植性”,用户可以自主管理身份和数据。
争议和未来展望 BlueSky 和 ATP 受到一些批评,例如“not invented here”方法和一些技术选择。一些人担心 ATP 的社会设置可能导致失败,因为缺乏社会激励和紧密联系的社区可能导致商业化和数据中心化。未来,如何解决社会激励、信任、安全等问题将决定 BlueSky 和 ATP 的长期发展。
HN 评论 84 comments | 作者:steveklabnik | 1 day ago #
https://news.ycombinator.com/item?id=39495355
根据您提供的链接,这篇帖子中的评论观点可以归纳为:
Bluesky 和 AT 协议存在技术优势,但采用了“not invented here”方法,可能导致不尊重他人和不愿意与他人交流的问题。
AT 协议在技术上可能更先进,但在社会设置上可能会失败,缺乏社会激励,可能导致商业化、广告插入、数据挖掘等问题。
对社交网络协议的评判不应仅从技术和对抗性的角度出发,也应考虑社会激励和用户参与感。
Bluesky 和 AT 协议的传输机制、用户身份、数据存储等方面存在讨论和疑问,需要进一步探讨和解决。
这些观点涵盖了对 Bluesky 和 AT 协议的技术、社会和传输机制等方面的讨论和看法。
Coroutines in C (2000) #
https://www.chiark.greenend.org.uk/~sgtatham/coroutines.html
这个链接提供了关于在 C 语言中实现协程的详细讨论。文章介绍了在大型程序中结构化的困难,以及当一个代码段产生数据,另一个代码段消耗数据时,应该如何确定调用者和被调用者的问题。作者提出了一种创造性的解决方案,即使用协程来解决这种结构问题。
文章详细讨论了如何在 C 语言中实现协程,包括使用静态变量和显式上下文结构两种方式。通过宏定义和 switch 语句的特性,作者展示了如何实现协程的返回和继续操作,避免了显式状态机的繁琐重写。最后,作者还提到了编码标准的问题,认为传统的编码标准在追求语法清晰的同时可能会牺牲算法清晰性,而使用协程可以更好地展现程序的算法结构。
HN 评论 67 comments | 作者:ColinWright | 9 hours ago #
https://news.ycombinator.com/item?id=39502276
根据您提供的链接,这篇帖子中的评论观点可以归纳为:
对 C 语言中的协程概念表示赞赏和兴趣。
讨论了 Simon Tatham 的网站和他的其他项目,如 PuTTY 和谜题集。
对使用 C++ 协程的经验进行分享,包括遇到的问题和优势。
讨论了使用 Duff’s device 和宏实现 C 协程的方法。
对使用线程和协程的选择进行了讨论,以及它们在实际代码中的应用和效果。
对使用 setjmp/longjmp 实现协程的讨论。
提到了 C++ lambda 的问题。
讨论了如何在 C 中实现生成器。
提到了与协程相关的其他话题和链接。
希望这个总结对您有帮助!
Osquery: An sqlite3 virtual table exposing operating system data to SQL #
osquery.io 网站内容摘要:

osquery 是一个性能卓越的终端可见性工具,可以像数据库一样查询您的设备。它使用基本的 SQL 命令来利用关系数据模型描述设备。osquery 使得理解基础架构变得简单,将操作系统呈现为高性能的关系数据库。通过 osquery,您可以查询设备上的各种信息,包括进程、主机信息等,以实现安全合规和 DevOps 目标。
osquery 具有以下三个重要特点:
快速且经过测试:其构建基础设施确保新引入的代码经过基准测试和验证。持续进行内存泄漏、线程安全性和二进制可重现性测试。
跨平台运行:支持 Windows、macOS、CentOS 以及自 2011 年以来发布的几乎所有 Linux 操作系统,无需依赖。osquery 助力一些最具挑战性的公司,包括 Facebook。
开源:osquery 采用 Apache 许可发布。自 2014 年开源以来,组织和个人贡献了越来越多的功能、工具和文档。
HN 评论 69 comments | 作者:signa11 | 10 hours ago #
https://news.ycombinator.com/item?id=39501281
根据您提供的链接,这篇帖子中的评论观点可以总结为:
Osquery 是一个很酷的项目,但存在许多技术债务,包括性能和安全债务,缺乏足够的关注和资金支持。
Osquery 在 MacOS 上使用良好,但可能存在正确性错误。
Osquery 被用作 Sophos 和 Alienvault 等 EDR 平台的基础层。
Osquery 在 Linux 磁盘空间使用方面的处理方式可能令人沮丧。
有人开始修复 osquery 的问题,但 GitHub 上仍有许多未解决的问题。
还提到了类似领域的其他项目,如 Steampipe 和 InfraSQL。
Osquery 曾是 Facebook 的开源项目,后来转交给社区,并成为 Linux Foundation 托管项目。
有关 SQLite 名称发音的讨论。
有人提到了开发的另一个项目“life query”。
有人提到了使用 Sqlite 虚拟表的经验。
有人讨论了如何将 osquery 构建到应用程序中。
有人对 Osquery 的实现和使用提出了一些质疑,包括性能和安全方面的问题。
有人认为 Osquery 是一个允许初级系统管理员一次性关闭所有机器或导致性能问题的不良想法。
有人提到了 Osquery 在大规模系统中的交互式广告探索功能。
有人认为 Osquery 的查询比 Shell 命令长,但对于不熟悉系统的人来说可能更容易使用。
有人提到了使用 Ansible 的方式。
希望这个总结对您有帮助!