2026-04-26 Hacker News Top Stories #
- 基于 RTL8159 的约 80 美元 10GbE USB 3.2 适配器更小更凉,台式机接 Gen2x2 可接近满速而 Mac 多在 6–7Gbps,低功耗且免驱(Win 需驱动),但若不追满速 2.5G/5G 更划算。
- Firefox 149 悄然集成 Brave 的 Rust 广告拦截引擎(兼容 uBO 语法)但默认未启用,同时继续在自家 MV3 中保留请求阻止 API,避免了 Chrome 式限制造成的拦截退化。
- 论文提出“学习力学”框架走向可检验的深度学习科学理论,聚焦训练动态与宏观规律以解释过参、隐式正则与 grokking 等现象并给出研究路径与开放问题。
- 有人将号称用 IBM 量子机破解 17 位 ECDLP 的项目后端替换为 /dev/urandom 仍获同等成功,揭示其“量子优势”实为随机+经典验证偏差并警示量子炒作风险。
- RØDECaster Duo 固件为未签名的 tar 包且默认启用仅公钥 SSH,作者逆向升级流程并自制固件开放更多访问方式后已上报厂商,呼吁在签名验证与用户控制间取得平衡。
- 从 Mockdown 等工具到纯文本会计实践,等宽字符与可组合的纯文本因便携、可审计与可长期保存在 AI 时代更显生命力。
- 经典美式餐车以火车车厢式流线设计与 24 小时亲民服务承载劳工阶层记忆,价格与法规随时代变化而升高但复古风仍在延续。
- OpenAI 推出 GPT-5.5/Pro,长任务一致性更强但偶有“偷懒”未严守指令,社区对其在大规模自动化中的性价比与风险仍有争议。
- WUPHF 以 Markdown+Git 构建 Karpathy 风格 LLM 维基供多智能体 24x7 协作沉淀知识,能减负与提效但仍需人类监督且难替代深度内化式笔记。
- Niri 26.04 引入 Wayland ext-background-effect 背景模糊并重构渲染提升性能与隐私,滚动平铺在多显示器与超宽屏上体验出色。
1. 全新 10 GbE USB 适配器更凉爽、更小巧、更便宜 (New 10 GbE USB adapters are cooler, smaller, cheaper) #
https://www.jeffgeerling.com/blog/2026/new-10-gbe-usb-adapters-cooler-smaller-cheaper/
本文介绍了一款基于 RTL8159 芯片的新型 10 GbE USB 3.2 以太网适配器,价格约 80 美元,体积小巧且散热表现良好,是传统笨重且昂贵的 Thunderbolt 10 GbE 适配器的潜在替代品。作者在四台不同配置的电脑上测试了该适配器,发现只有配备 USB 3.2 Gen 2x2(20 Gbps)接口的台式机能够达到接近满速的 10 Gbps 传输速度,其他设备如 MacBook 和 Framework 笔记本的速度则在 6-7 Gbps 左右。
适配器在 Mac 和 Windows 系统上的兼容性表现不同,Mac 无需额外驱动即可使用,但 Windows 需要安装 Realtek 官方驱动。测试还显示,Mac 设备的上传下载速度较为对称,而 Framework 笔记本的上传速度明显低于下载速度。
文章指出,USB 接口的命名和实际带宽常让用户困惑,Windows 系统对 USB 端口速度的显示也不够直观,建议用户查看设备规格以确认支持的 USB 版本。
对于不需要满 10 Gbps 速度的用户,2.5 Gbps 或 5 Gbps 的 USB 适配器性价比更高,尤其是在价格和实际速度提升方面更为合理。该 10 GbE 适配器适合已有 10 Gbps 网络且使用 RJ45 接口的用户,且希望获得更小巧、散热更好的设备。
此外,作者简单测试了适配器的功耗和温度,发现其功耗较低(约 0.86 瓦),运行时温度最高约 42.5 摄氏度,远低于传统 Aquantia 芯片适配器的高温表现。
总结来看,这款基于 RTL8159 芯片的 10 GbE USB 适配器为用户提供了一个更便宜、更快且更便携的选择,尤其适合支持 USB 3.2 Gen 2x2 接口的设备。市场上还有其他类似产品,且也有 PCI Express 版本可供台式机用户选择,进一步丰富了 10 GbE 网络接入的方案。
HN 热度 530 points | 评论 308 comments | 作者:calcifer | 18 hours ago #
https://news.ycombinator.com/item?id=47899053
- iperf3 默认单线程,可能限制测试速度,使用多线程参数可更准确反映硬件性能。
- 现代 CPU 核心性能足够支持 10Gbps USB 传输,多线程在低性能设备上提升明显。
- 以太网芯片普遍支持自适应中断合并,减少中断带来的性能瓶颈。
- iperf(版本 2)支持多线程,可能更适合多线程性能测试。
- 单线程测试更能反映实际应用性能,因为大多数应用不会使用多线程传输。
- 测试目的是评估适配器性能,独立于 CPU 和系统整体性能。
- Steam 下载速度受限于安装速度,不能作为网络速度参考。
- USB 版本命名混乱,消费者难以理解不同版本的实际速度。
- USB 3.2 标准本身不代表端口或设备的实际性能,速度与具体版本和接口类型相关。
- USB 5Gbps 实际速率约为 4Gbps,10Gbps 和 20Gbps 版本速度更接近标称值。
- USB 端口标注速度并不总是准确,实际连接速度受设备和线缆限制。
- USB 设备连接速度通常取决于链路中最低速的设备,不能简单以端口标识判断。
- USB 4 和 Thunderbolt 设备理论上兼容 USB 3.2 2x2 速度,但实际支持情况可能存在差异。
- USB 版本命名的复杂和混乱主要源于标准重命名和市场营销,非技术本身问题。
- Thunderbolt 相较于 USB-C 提供更稳定的速度和充电标准。
- USB 3.2 版本命名曾多次变更,导致消费者对速度和版本的理解困难。
- USB 3.2 Gen 1x2 物理接口不同但速度与 Gen 2x1 相同,实际设备较少使用。
- USB 5Gbps 的“b”代表波特率,非误导性营销。
2. Firefox 已集成 Brave 的广告拦截引擎 (Firefox Has Integrated Brave’s Adblock Engine) #
https://itsfoss.com/news/firefox-ships-brave-adblock-engine/
这篇文章介绍了 Firefox 浏览器在版本 149 中悄然集成了 Brave 浏览器的广告拦截引擎 adblock-rust。该引擎是基于 Rust 语言开发的开源广告和跟踪屏蔽工具,具有网络请求阻止、美化过滤等功能,并兼容 uBlock Origin 的过滤列表语法。虽然这一变化没有出现在官方发布说明中,但由 Mozilla 工程师 Benjamin VanderSloot 通过 Bugzilla 提交并实现。
文章还提到,Firefox 默认并未启用该引擎,也没有提供用户界面或过滤列表。Waterfox 浏览器作为 Firefox 的一个分支,也采用了 adblock-rust,基于 Firefox 的实现进行构建。
如果读者想体验这项实验性功能,可以通过 about:config 页面开启相关设置,并添加 EasyList 和 EasyPrivacy 过滤列表。测试时需关闭 Firefox 自带的增强跟踪保护,以确保 adblock-rust 在屏蔽广告时发挥作用。实际测试显示,广告位仍然保留,但广告内容被屏蔽,只显示“Advertisement”文字。
文章最后呼吁支持独立的 Linux 新闻报道,并介绍了 It’s FOSS Plus 会员的福利,包括免费电子书、无广告阅读体验和社区徽章等。作者 Sourav Rudra 是一位热衷开源软件和定制 PC 的技术爱好者。
HN 热度 373 points | 评论 220 comments | 作者:nreece | 22 hours ago #
https://news.ycombinator.com/item?id=47897891
- Firefox 正在测试 Brave 开源的 Rust 广告拦截引擎,以提升内置的增强跟踪保护功能,但并未放弃 MV2 扩展,确保广告拦截插件继续有效。
- Firefox 的 MV3 实现仍支持请求阻止 API,与 Chrome 不同,Chrome 在 MV3 中移除了该功能,导致广告拦截效果受限。
- 由于 Chrome 限制了规则数量和表达式类型,MV3 可能影响过滤列表的及时更新,但 Firefox 提供了完整的 API 支持,避免了此问题。
- 其他基于 Chromium 的浏览器大多继承了 Chrome 的 MV3 限制,只有 Firefox 保持了对请求阻止的支持。
- Rust 代码的引入提升了浏览器的内存安全性,减少安全漏洞风险,Mozilla 在 Firefox 中大量采用 Rust 语言。
- 广告拦截是扩展 API 的核心功能,支持 uBlock Origin 等主流广告拦截插件对用户体验至关重要。
- 社交媒体和技术媒体对 MV3 的误解和夸大报道导致了用户的恐慌和误解。
- Firefox 未来可能会逐步弃用 MV2,但前提是确保广告拦截插件的功能不受影响。
- Safari 等非 Chromium 浏览器也在积极维护自己的扩展生态,Firefox 在这方面保持领先。
- 非 Chrome 的 Chromium 浏览器应联合支持 MV3 的请求阻止功能,以区别于 Chrome 并提升用户体验。
3. 深度学习将拥有科学理论 (There Will Be a Scientific Theory of Deep Learning) #
https://arxiv.org/abs/2604.21691
该网页展示了一篇题为《There Will Be a Scientific Theory of Deep Learning》的学术论文,发表于 2026 年 4 月 23 日,作者包括 Jamie Simon 及其他 13 位合作者。论文主张深度学习正在形成一套科学理论,这套理论能够描述神经网络训练过程中的关键属性和统计特征,包括训练动态、隐藏表示、最终权重及性能表现。
论文总结了五个主要研究方向,指向这套理论的形成:(a)可解的理想化模型帮助理解现实系统中的学习动态;(b)可处理的极限条件揭示基本学习现象;(c)简单的数学规律捕捉重要的宏观观测量;(d)超参数理论将其与训练过程其他部分区分开,简化系统分析;(e)不同系统和环境中共享的普遍行为,明确哪些现象需要解释。
这些研究方向共同关注训练过程的动态,侧重描述粗略的统计特征,并强调可被验证的定量预测。作者提出将这套理论称为“学习力学”,并讨论了其与统计学和信息论视角的关系,尤其预期学习力学与机制可解释性之间将形成互补关系。
此外,论文回应了关于深度学习理论不可行或不重要的常见质疑,最后展望了学习力学的重要开放问题,并为初学者提供了建议。网页还提供了论文的 PDF 下载链接和进一步的入门材料及开放问题的在线资源。
HN 热度 338 points | 评论 150 comments | 作者:jamie-simon | 1 day ago #
https://news.ycombinator.com/item?id=47893779
- 目前对深度学习的科学理论研究正在逐步完善,尤其是关于“为什么神经网络比其他模型表现更好”的问题接近有了较为明确的答案。
- 许多研究成果尚未普及到公众,理论指导实际网络设计的能力仍有限,更多是通过经验反推理论。
- 信息论基础为深度学习提供了坚实的理论支撑,模型的效率提升和信息损失的最小化是关键。
- 目前行业资金更多倾向于追求更大规模模型,而非提高模型效率和持久性。
- 深度学习从“预测计算器”向“持久系统”转变涉及非平衡热力学问题,有相关数学和基本定律可借鉴。
- AI 领域在某些基础理论上重复学习其他学科已掌握的原理,存在资源和效率浪费。
- 过度参数化和神经网络架构的某些现象在传统统计学偏差-方差权衡理论下难以解释。
- 许多人对神经网络的研究持怀疑态度,认为其是黑箱难以理解,但实际研究仍有很大潜力。
- 通用逼近定理虽证明了神经网络的表达能力,但并不能解释其为何优于其他模型。
- 神经网络的“隐式正则化”机制类似于信息压缩,是其性能优越的关键因素。
- “grokking”现象(模型先记忆后泛化)对压缩视角提出挑战,可能需要额外机制解释。
- 资金和激励机制限制了跨学科理论成果在 AI 领域的应用和推广。
4. 将 IBM 量子计算机后端替换为/dev/urandom (Replace IBM Quantum back end with /dev/urandom) #
https://github.com/yuvadm/quantumslop/blob/25ad2e76ae58baa96f6219742459407db9dd17f5/URANDOM_DEMO.md
该网页内容主要介绍了一个名为“quantumslop”项目中的实验,该项目声称利用量子计算机对椭圆曲线离散对数问题(ECDLP)进行攻击,实现了对最多 17 位曲线的密钥恢复。网页重点描述了对项目代码中的关键函数 solve_ecdlp()进行了修改,将原本调用 IBM 量子计算机后端的部分替换为使用操作系统的随机数生成器(/dev/urandom),以测试量子计算机是否真正贡献了有效信号。
实验结果显示,使用纯随机数生成器替代量子硬件后,密钥恢复的成功率与原先使用 IBM 量子计算机时几乎无差异,表明所谓的量子攻击结果实际上可能是随机噪声的产物。具体测试包括多个不同位数的挑战,从 4 位到 17 位,均在多次尝试中成功恢复了密钥,且恢复率符合理论上随机猜测的概率。
网页进一步分析了该现象的原因,指出作者的提取方法对每次测量结果进行验证,只要随机生成的候选密钥满足经典验证条件就被接受,因此在大量随机尝试下,成功恢复密钥的概率很高。尤其是在样本数远大于群阶的情况下,随机噪声本身就能高概率地“恢复”密钥。
最后,网页提供了复现该实验的步骤和命令,强调该项目的所谓量子优势实际上是由于统计概率和验证机制导致的误判,而非量子计算机真正发挥了作用。
HN 热度 329 points | 评论 44 comments | 作者:pigeons | 23 hours ago #
https://news.ycombinator.com/item?id=47897647
- 项目 11 颁发的 1 BTC 奖励给了一个用 IBM 量子硬件破解 17 位椭圆曲线密钥的成果,但有人用/dev/urandom 替代量子计算机后依然能恢复密钥,说明量子计算机并未真正贡献计算能力。
- 量子硬件在破解速度上并不比随机数生成器快,甚至可能更慢,且代码中大量经典计算和网络调用使整体速度受限。
- 破解 17 位 ECC 密钥对于当前经典计算机来说非常简单,项目 11 未能正确验证提交结果,导致奖励了一个实际上是经典算法的解决方案。
- 该解决方案的作者缺乏量子计算背景,代码风格和提交历史显示其更像是经典软件开发者的作品。
- 量子计算机的贡献被质疑为“噪声”,实际算法主要依赖经典概率方法,量子部分无实质性作用。
- 成功率与速度是两个不同维度,虽然成功率相似,但量子计算机并未表现出明显优势。
- 量子计算的演示更多是物理实验性质,而非实用的计算任务,破解小规模密钥缺乏实际意义。
- “去量子化”是量子信息研究中的合理方法,有助于区分真正的量子优势与伪装。
- 如果量子计算机的表现与随机猜测无异,则该技术并未展示出超越经典计算的价值。
- 量子技术在加密货币领域可能被滥用,存在“量子诈骗”的风险,需警惕相关炒作。
5. 我的音频接口默认启用 SSH (My audio interface has SSH enabled by default) #
https://hhh.hn/rodecaster-duo-fw/
这篇文章讲述了作者购买并使用 Rodecaster Duo 音频接口的经历。作者购买该设备是为了方便自己和女友在同一房间使用各自的麦克风进行游戏和 Discord 通话,避免回声问题,同时能方便地切换到工作电脑使用。作者对该设备的使用体验非常满意,推荐给有类似需求的人。
文章重点描述了作者在固件更新过程中的探索。作者发现固件更新文件以 gzipped tarball 格式存储,设备有两个分区以防止刷机失败导致设备变砖。固件更新没有签名校验,设备默认启用了 SSH 服务,且只允许公钥认证,作者还列出了默认的 SSH 公钥。
作者通过抓包工具 Wireshark 分析了 Windows 环境下的固件更新流程,发现更新通过 HID 命令控制,先发送’M’命令进入更新模式,挂载设备后复制固件文件,再发送’U’命令触发刷机。作者基于此制作了自定义固件,实现了通过 SSH 密码认证和添加自定义公钥的功能,从而能够远程访问设备。
总结部分,作者对设备的开放性和易刷固件感到惊喜,认为这是拥有设备的乐趣所在。虽然不清楚为何默认启用 SSH 及添加默认密钥,但已向 RODE 官方提交了安全报告。整体上,作者对 RODE 产品非常喜爱,期待未来继续购买更多设备。文章最后提供了联系方式,欢迎读者提问交流。
HN 热度 310 points | 评论 96 comments | 作者:hhh | 1 day ago #
https://news.ycombinator.com/item?id=47894747
- 固件签名和开放固件并非对立,理想状态是默认开启验证,但允许用户自行管理密钥或通过硬件操作切换,赋予硬件所有者控制权。
- 设备应在首次设置或恢复出厂时允许用户选择开发者控制或所有者控制,防止物理访问者暗中植入后门,并在启动时显示警告提示设备被篡改。
- 固件以简单的 tar 包加哈希形式存在,方便用户自行升级,避免复杂的升级流程。
- 一些设备如 Zoom R 系列可作为 USB 音频接口使用,但部分功能(如推子)在该模式下无效,且有时会自动开启效果,用户更倾向在 DAW 中处理效果。
- 固件升级应支持通过 FTP、SCP 等简单方式上传,配合校验机制保证数据完整性,避免升级过程复杂化。
- 允许通过硬件开关进入固件升级模式(如 TFTP),可实现设备的“不可变砖”状态,方便实验和恢复。
- 校验机制主要保障数据完整性和设备可用性,而非单纯防止恶意攻击,需明确安全保护对象是用户还是厂商。
- 固件升级应设计物理确认步骤(如按键操作)以防止误刷或恶意刷写,避免设备被刷成无法使用状态。
- 不希望音频接口默认开启 SSH 服务,避免出现未经授权的访问风险。
- 固件未加密或签名使得用户可以自由修改固件,且不会增加厂商负担。
- 设备不应将 SSH 服务暴露在公共网络,以降低安全风险。
- 现代音频接口实际上是运行完整 64 位 Linux 系统的计算机,功能复杂且可扩展。
6. 纯文本已流传数十年,并将继续存在 (Plain text has been around for decades and it’s here to stay) #
https://unsung.aresluna.org/plain-text-has-been-around-for-decades-and-its-here-to-stay/
这篇博客文章由 Marcin Wichary 撰写,主题围绕“纯文本”或“ASCII”图表和界面设计工具展开。作者介绍了几款相关工具,包括 Mockdown(支持网页和移动端)、Wiretext(网页端,桌面使用)以及 Mac 应用 Monodraw。这些工具适合喜欢有限视觉选择、用于源代码中低调图表绘制的人群,同时也逐渐成为生成式人工智能的切入点。
文章指出,这类工具的有趣之处在于它们是对 20 世纪 70 至 80 年代文本用户界面(如 TUI 和 Turbo Vision)的一种现代演绎,结合了现代的性能、网页访问能力以及鼠标和触控板的操作便利性。作者强调,约束条件下的设计实践将变得越来越重要,既能简化创作过程,也能在人工智能兴起的背景下增加挑战性。
此外,作者赞赏等宽纯文本的持久生命力,不仅因为其文件格式的便携性,更因为文本编辑作为界面本身的强大和广泛熟悉度。文章还特别提到 Mockdown 中的 ASCII 喷绘功能非常有趣。整体来看,文章通过介绍和分析这些工具,表达了对纯文本图形设计及其未来潜力的肯定和期待。
HN 热度 265 points | 评论 133 comments | 作者:rbanffy | 23 hours ago #
https://news.ycombinator.com/item?id=47897681
- 纯文本会计系统如 Beancount+Fava 比 QuickBooks 更简洁高效,支持文本发票、里程追踪和验证,且无广告干扰,利用 git 和时间戳可证明数据修改时间。
- 多币种处理在传统软件中较难,纯文本格式便于自定义和转换,且可以编写脚本或用 AI 辅助迁移数据。
- 使用 RFC3161 时间戳和比特币时间戳为 git 提交做时间认证,虽然审计价值有限,但增加了数据不可篡改的可信度。
- 保持数据可导出为通用格式(如 CSV)是设计纯文本会计系统的重要考虑,便于与会计师或其他工具兼容。
- QuickBooks 导出功能不完整,无法包含所有手工录入的细节,导致用户转向自主管理的纯文本系统。
- 20 世纪 70-90 年代的文本用户界面(TUI)有其独特优势,如高分辨率文本模式和鼠标支持,带来良好使用体验。
- 经典文本编辑器和开发环境(如 Borland、Wordperfect、Emacs)在文本界面中表现出色,且 Emacs 因高度可配置和集成 AI 被视为未来操作系统。
- 纯文本界面操作减少对鼠标依赖,有助于缓解腕管综合症,但键盘操作也可能导致类似问题,良好的人机交互设备很重要。
- 现代 TUI 和基于文本的操作系统(如 Omarchy)正逐渐兴起,未来可能以文本对话为主界面,融合 AI 技术提升效率。
7. 经典的美国餐车 (The Classic American Diner) #
https://blogs.loc.gov/picturethis/2026/04/the-classic-american-diner/
这篇博客文章介绍了经典的美国餐车(diner),强调了餐车作为美国饮食文化独特组成部分的重要性。虽然如今餐车不如过去普遍,但它们依然点缀在美国各地,带有浓厚的怀旧气息。
文章提到许多餐车设计模仿火车车厢的流线型外观,这种设计便于运输和安装。举例说明了佐治亚州哥伦布市一家结合美式和韩式料理的餐车,以及佛蒙特州切斯特的 Country Girl Diner,这些餐车都采用了典型的银色波纹金属外观,入口设计也考虑了保温功能。
通过历史照片,文章展示了不同年代餐车的菜单和价格,如 1940 年马里兰州餐车中 5 美分的热狗和 25 美分的套餐,以及 1959 年纽约市餐车中 75 美分的早餐套餐。照片还揭示了餐车顾客的社会背景,例如 1940 年代纽约附近餐车主要服务卡车司机,许多餐车全天候营业以满足长时间工作的顾客需求。
近十年的照片显示,餐车依然存在,且常常保留或复刻 20 世纪中叶的设计风格和氛围,如田纳西州 Pigeon Forge 的 Sunliner Diner 和亚利桑那州凤凰城的 5 & Diner,后者以 50 年代风格的装饰和服务吸引顾客。
文章最后表达了作者对餐车的怀念和对读者可能去体验餐车的鼓励,并附带了相关照片和档案的链接,方便读者进一步探索美国餐车文化。评论区中读者也分享了自己与餐车的美好回忆。
HN 热度 257 points | 评论 152 comments | 作者:NaOH | 1 day ago #
https://news.ycombinator.com/item?id=47894435
- 经典美式餐厅注重服务细节,环境私密且有安全保障,服务效率高,顾客体验好。
- 餐厅租金成本高导致服务空间受限,低成本地区更常见包间。
- 1940 年代和 1950 年代的热狗和汉堡价格换算到现在约为 1-8 美元左右。
- 份量可能也随时间增加,存在“份量膨胀”现象。
- 现代餐饮业的法规和合规成本远高于过去,推高了价格。
- 餐厅成本结构大致为 30% 食材、30% 人工、30% 运营、10% 利润。
- 固定成本如人工和保险导致淡季时单品成本上升,价格上涨可能进一步减少客流,形成恶性循环。
- 保险费用中部分是随销售额调整的,不完全是固定成本。
- 美国餐厅普遍存在“份量失真”,汉堡和热狗份量标准化但整体份量较过去大。
- 份量增加可能是餐厅应对通胀的一种策略,让价格上涨显得不那么明显。
- 劳动力成本增长快于食材成本,份量膨胀是餐厅合理应对方式。
- 经典的四分之一磅汉堡是消费者熟悉的份量参考。
- 餐厅份量自 20 世纪中期以来明显增大,尽管近年略有回落。
- 通胀计算显示 1945 年至今价格约涨 20 倍,但实际餐厅价格可能高于通胀调整值。
- 现代餐厅汉堡价格高于历史通胀调整价格,可能因人工成本占比增加。
- 餐厅成本中人工约占 30%,食材成本下降,运营成本占 20-30%,利润较低。
8. OpenAI 在 API 中发布 GPT-5.5 和 GPT-5.5 Pro (OpenAI releases GPT-5.5 and GPT-5.5 Pro in the API) #
https://developers.openai.com/api/docs/changelog
该网页是 OpenAI 官方文档和资源的综合导航页面,主要面向开发者和技术人员,内容涵盖了 OpenAI 的 API、模型、工具和开发指南。页面结构清晰,分为多个模块,包括 API 参考、Codex(代码生成)、ChatGPT、应用开发 SDK、商业集成、社区资源等。
主要内容包括:
- API 相关文档:详细介绍了 API 的端点、参数、响应格式,以及文本生成、代码生成、图像和语音处理等功能的使用方法。
- Codex 专区:提供了使用 Codex 模型进行代码生成和自动化的示例、最佳实践和工作流程。
- ChatGPT 及其扩展:涵盖了 ChatGPT 的应用开发、定制化、插件开发和多模态能力。
- 工具与集成:介绍了各种开发工具,如实时 API、语音代理、文件检索、代码解释器等,帮助开发者构建复杂应用。
- 安全与优化:包含安全最佳实践、模型优化、成本管理和生产环境部署的指导。
- 社区与学习资源:提供了教程、示例应用、博客、视频和开发者社区的链接,支持开发者学习和交流。
此外,页面还包含了最新版本信息、更新日志、即将废弃功能提示,以及多种开发环境和平台的支持说明,帮助用户快速上手并高效使用 OpenAI 的技术。整体内容丰富,适合希望深入了解和使用 OpenAI 技术的开发者参考。
HN 热度 254 points | 评论 151 comments | 作者:arabicalories | 1 day ago #
https://news.ycombinator.com/item?id=47894000
- GPT-5.5 在执行用户指令时有时表现懒散,未能完全按照要求输出代码,令付费用户感到不满。
- 近几代模型改进有限,更多是在不同方面做权衡调整。
- GPT-5.5 在处理长任务时表现显著提升,能够保持较好的一致性。
- 长期运行的自动化任务尚未完成,结果仍未知,存在不确定性。
- 有用户用 GPT-5.5 自动化重写内核模块,结合多模型和复杂流程,产出代码质量接近人工仔细编写。
- 大规模使用多账户轮换调用 API,月成本高达十万美元以上,但实际支付较少。
- 许多人低估了 AI 结合多工具和流程后的能力,问题更多出在提示设计和资源限制。
- 有人质疑这种大规模自动化任务的实际价值和风险,担心最终结果不理想。
- 对 AI 未来发展的看法分歧,有人认为 AI 会持续爆发式进步,也有人持怀疑态度。
- 通过 AI 获得巨大生产力提升的案例不多,部分开发者未能充分利用生成式 AI。
- 有人希望作者能分享更多自动化任务的细节和成果,但也有人对此持否定态度。
- 由于成本补贴,失败的代价被弱化,用户可能不会感受到真正的惩罚。
9. 展示 HN:一个由你的智能代理维护的 Karpathy 风格大型语言模型维基(Markdown 和 Git) (Show HN: A Karpathy-style LLM wiki your agents maintain (Markdown and Git)) #
https://github.com/nex-crm/wuphf
该网页是一个名为 WUPHF 的项目主页,介绍了一个为 AI 员工设计的协作办公平台,类似于 Slack,但具备共享大脑的功能。该平台旨在实现全天候(24x7)运行的智能工作环境,支持 AI 员工之间的高效沟通与协作。
页面内容主要包括项目的代码库结构、最新的提交记录和开发动态,展示了项目的活跃开发状态和持续迭代。页面还列出了项目的多个文件夹和文件,如代码、文档、测试数据、配置文件等,反映出项目的完整性和系统性。
此外,页面顶部导航提供了丰富的功能入口,包括代码创建、开发者工作流、安全保障、行业解决方案、资源支持和社区活动等,显示该项目依托于 GitHub 平台,具备完善的生态支持和多样的应用场景。
总体来看,该网页是一个面向开发者和技术人员的项目展示平台,详细介绍了 WUPHF 项目的功能定位、技术架构和开发进展,强调了其作为 AI 协作办公工具的创新性和实用性。
HN 热度 220 points | 评论 103 comments | 作者:najmuzzaman | 15 hours ago #
https://news.ycombinator.com/item?id=47899844
- 自动化笔记可能无法替代通过批判性阅读和构建个人认知模型而形成的笔记价值,笔记的核心是理解和内化知识。
- 该系统不仅仅是笔记工具,更是多智能体协作的框架,旨在将认知负担部分转移给共享的 LLM“脑”,但是否能创造真正有价值的产品仍存疑。
- 通过智能体框架提升团队生产力,尤其是非技术人员,可以实现产出成倍增长和更易审核的成果,但仍需人类提供结果指导。
- 该系统适合快速搭建业务蓝图和实验,虽然不能替代深度的知识内化,但能减轻阅读和结构化知识的工作量。
- “不做规模化的事情”的原则依然适用,只是具体的“不做规模化”的内容会发生变化。
- 大量利用 AI 完成繁琐工作但不加以利用,造成资源浪费。
- 目前写作多,阅读少,导致信息利用效率低下。
- 软件工程中,阅读代码的时间远多于编写代码,强调阅读的重要性。
10. Niri 26.04:可滚动平铺式 Wayland 合成器 (Niri 26.04: Scrollable-tiling Wayland compositor) #
https://github.com/niri-wm/niri/releases/tag/v26.04
该网页介绍了 Niri 项目的最新版本 v26.04 的发布情况。Niri 是一个基于 Wayland 的可滚动平铺式窗口管理器,窗口以列的形式排列在一个无限向右延伸的条带上,打开新窗口不会导致已有窗口大小变化。项目现已迁移至 GitHub 组织,以便更好地管理和分配权限,并感谢社区成员对问题和拉取请求的积极贡献。
本次更新的最大亮点是引入了备受期待的模糊效果功能,这是 Niri 用户最常请求的特性。模糊效果通过 Wayland 的 ext-background-effect 协议实现,支持窗口和层壳组件请求背景模糊。多个应用和工具包已经支持或计划支持该功能,如 Dank Material Shell、Noctalia shell、foot 终端、kitty 终端等。对于不支持该协议的应用,可以通过 Niri 配置文件手动启用模糊。
模糊效果分为普通模糊和 xray 模糊两种,xray 模糊默认启用,效率更高,因为它只需计算一次模糊的壁纸图像并重复使用,适合静态背景。普通模糊则在每帧渲染时实时处理,适合需要更真实模糊效果的场景。用户可以通过配置选择不同层级的模糊类型。
实现背景模糊功能是一个复杂的工程,涉及大量代码重构和性能优化,特别是在渲染架构和窗口位置管理方面。Niri 还解决了模糊效果与其他功能的兼容性问题,如屏幕录制时的隐私保护,确保敏感内容不会被误泄露。
此外,项目还更新了服务文件,提升了兼容性和结构,最低支持的 Rust 版本提升至 1.85。整体来看,此次更新极大丰富了 Niri 的视觉效果和用户体验,标志着项目的一个重要里程碑。
HN 热度 213 points | 评论 63 comments | 作者:nickjj | 8 hours ago #
https://news.ycombinator.com/item?id=47902416
- Niri 被认为是非常优秀的 Wayland 合成器,用户切换到 Niri 后体验显著提升,尤其是在 Arch Linux 系统上支持良好。
- Niri 与超宽曲面显示器搭配使用效果极佳,能充分利用屏幕空间,提升使用体验。
- Niri 相比其他窗口管理器(如 Qtile、Sway、Hyprland)更自然、稳定,支持多显示器管理表现优异。
- Omarchy 和 Hyprland 也引入了类似的滚动窗口管理功能,但 Niri 在稳定性和整体设计上更胜一筹。
- OmniWM 在 Mac 上实现了类似 Niri 的布局,提升了 MacOS 上的窗口管理体验。
- 有用户认为 Niri 的滚动窗口管理模式使得工作流程更灵活,不再需要严格组织窗口,减少了管理窗口的认知负担。
- 传统的平铺窗口管理器要求用户高度组织窗口,而 Niri 允许更随意的窗口布局,虽然有时查找窗口不够直观,但可以通过概览和搜索功能弥补。
- 有用户从 KDE 切换到 Niri 后,感受到窗口管理更轻量,窗口并排显示代替了重叠,提升了操作流畅度。
- Niri 支持按工作区划分活动,用户可以在不同工作区中保持不同项目的窗口,避免因窗口过多而关闭应用。
- 有用户对 Niri 的演示视频不满意,认为视频效果可能影响潜在用户的尝试意愿。
Hacker News 精彩评论及翻译 #
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886400
Open Source as it gets in this space, top notch developer documentation, and prices insanely low, while delivering frontier model capabilities. So basically, this is from hackers to hackers. Loving it!
Also, note that there’s zero CUDA dependency. It runs entirely on Huawei chips. In other words, Chinese ecosystem has delivered a complete AI stack. Like it or not, that’s a big news. But what’s there not to like when monopolies break down?
jari_mustonen
这是该领域中尽可能开源的项目,开发者文档一流,价格异常低廉,同时提供前沿的模型能力。基本上,这是黑客为黑客打造的。非常喜欢!
另外,注意这里完全不依赖CUDA。它完全运行在华为芯片上。换句话说,中国生态系统已经打造了完整的AI技术栈。不管喜欢与否,这都是一条重要的消息。垄断被打破,有什么不值得高兴的呢?
US special forces soldier arrested after allegedly… #
https://news.ycombinator.com/item?id=47885819
That’s hilarious … so he’s arrested and put on trial and all the senate and congress are doing the exact same and free? lol
looksjjhg
太搞笑了……他被逮捕并受审,而参议院和国会所有人都做着同样的事却自由自在?哈哈
Meta tells staff it will cut 10% of jobs #
https://news.ycombinator.com/item?id=47885509
3 and a half ways AI takes jobs:
-
By making workers unnecessary (largely hypothetical right now?)
-
By companies spending big on AI, but it didn’t pay off yet so they need to cut back on something else.
-
AI is a good excuse for layoffs they want to do anyway.
Also - the investors would rather hear “AI” than “oops we are in trouble so we need to do layoffs”. For example, if you spent a lot of billions on a 2nd life clone with fewer players than developers …
wisty
AI导致失业的三种半种方式:
-
让工人变得不必要(目前大多还只是理论上的?)
-
公司在AI上投入巨大,但因为还没见到回报,所以需要在其他方面削减开支。
-
AI成为他们本来就想裁员的一个好借口。
另外,投资者更愿意听到“AI”这个词,而不是“哎呀,我们遇到麻烦了,所以需要裁员”。比如说,如果你花了数十亿美元开发一个活跃用户比开发者还少的《第二人生》克隆版……
US special forces soldier arrested after allegedly… #
https://news.ycombinator.com/item?id=47886442
Only aristocrats can play that game. The soldier is being punished for doing something not allowed for his class status.
This is how a caste system works. People is not judged based on their actions but their relationship to power.
Frieren
只有贵族才能玩那个游戏。士兵因为做了自己身份阶级不允许的事情而受到惩罚。
这就是种姓制度的运作方式。人们不是根据他们的行为来评判,而是根据他们与权力的关系来评判。
Meta tells staff it will cut 10% of jobs #
https://news.ycombinator.com/item?id=47885407
This is interesting because it’s a case of “AI taking jobs” but not in the way people normally mean; these massive layoffs are happening not because AI is doing the work they used to do but because capex is sucking all of the operating money out of everywhere. The companies may be forced to replace some of the laid-off employees with AI (as far as possible) but that’s an effect not a cause.
bandrami
这很有趣,因为这是“人工智能抢工作”的一种情况,但并不是人们通常所指的那种;这些大规模裁员发生的原因不是因为人工智能在做他们以前的工作,而是因为资本支出正在吸走所有地方的运营资金。公司可能被迫用人工智能来替代部分被裁员工(在可能的情况下),但那是一个结果,而不是原因。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886972
I always find it an illuminating experience about the power of mass propaganda every time I see an American believe they somewhat have the moral high ground over China, despite starting a new war somewhere around the globe either for petrol or on behalf of Israel every six months.
Ladioss
每次看到美国人认为自己在道德上比中国更高尚时,我总会深刻体会到大众宣传的强大力量,尽管美国几乎每六个月就会为了石油或代表以色列在全球某地发动一场新的战争。
I cancelled Claude: Token issues, declining qualit… #
https://news.ycombinator.com/item?id=47893895
I write detailed specs. Multifile with example code. In markdown.
Then hand over to Claude Sonnet.
With hard requirements listed, I found out that the generated code missed requirements, had duplicate code or even unnecessary code wrangling data (mapping objects into new objects of narrower types when won’t be needed) along with tests that fake and work around to pass.
So turns out that I’m not writing code but I’m reading lots of code.
The fact that I know first hand prior to Gen AI is that writing code is way easier. It is reading the code, understanding it and making a mental model that’s way more labour intensive.
Therefore I need more time and effort with Gen AI than I needed before because I need to read a lot of code, understand it and ensure it adheres to what mental model I have.
Hence Gen AI at this price point which Anthropic offers is a net negative for me because I am not vibe coding, I’m building real software that real humans depend upon and my users deserve better attention and focus from me hence I’ll be cancelling my subscription shortly.
wg0
我写详细的规格说明。多文件,附带示例代码。用Markdown格式。
然后交给Claude Sonnet。
有了明确的硬性需求,我发现生成的代码漏了需求,有重复代码,甚至有不必要的数据处理(比如把对象映射成类型更窄的新对象,而其实不需要),还有那些通过造假和变通来通过测试的代码。
所以事实证明,我不是在写代码,而是在看大量代码。
我亲身经历过的情况是,写代码其实容易得多。真正费力的是阅读代码,理解代码,构建心理模型。
因此,我用生成式AI反而比以前花更多时间和精力,因为我得读很多代码,理解它们,并确保它们符合我的心理模型。
因此,Anthropic这个价格点的生成式AI对我而言是净负面影响,因为我不是在随意写写代码,我在构建真正能被实际用户依赖的软件,而我的用户理应得到我更多关注和专注,所以我很快就会取消订阅。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886696
There are quite a few comments here about benchmark and coding performance. I would like to offer some opinions regarding its capacity for mathematics problems in an active research setting.
I have a collection of novel probability and statistics problems at the masters and PhD level with varying degrees of feasibility. My test suite involves running these problems through first (often with about 2-6 papers for context) and then requesting a rigorous proof as followup. Since the problems are pretty tough, there is no quantitative measure of performance here, I’m just judging based on how useful the output is toward outlining a solution that would hopefully become publishable.
Just prior to this model, Gemini led the pack, with GPT-5 as a close second. No other model came anywhere near these two (no, not even Claude). Gemini would sometimes have incredible insight for some of the harder problems (insightful guesses on relevant procedures are often most useful in research), but both of them tend to struggle with outlining a concrete proof in a single followup prompt. This DeepSeek V4 Pro with max thinking does remarkably well here. I’m not seeing the same level of insights in the first response as Gemini (closer to GPT-5), but it often gets much better in the followup, and the proofs can be very impressive; nearly complete in several cases.
Given that both Gemini and DeepSeek also seem to lead on token performance, I’m guessing that might play a role in their capacity for these types of problems. It’s probably more a matter of just how far they can get in a sensible computational budget.
Despite what the benchmarks seem to show, this feels like a huge step up for open-weight models. Bravo to the DeepSeek team!
hodgehog11
这里有不少关于基准测试和编码性能的评论。我想就它在实际科研环境中解决数学问题的能力提出一些看法。
我手头有一套硕士和博士水平的新颖概率与统计问题,难度各异。我的测试流程是先输入这些问题(通常附带约2-6篇相关论文作为背景资料),然后再请求其给出严密的证明作为后续回答。由于这些问题相当困难,这里没有量化的性能评估,我只是根据输出对解决方案的帮助程度来判断,理想情况下希望能生成可发表的成果。
在这个模型之前,Gemini是领先者,GPT-5紧随其后。没有其他模型能接近这两者(不,包括Claude也不行)。Gemini在一些较难问题上偶尔会有惊人的洞见(对相关方法的有见地猜测在科研中非常有价值),但这两个模型通常都难以在一次后续回答中勾勒出具体的严谨证明。DeepSeek V4 Pro开启最大思考后,在这方面表现非常出色。我观察到其首次回答的洞见不如Gemini(更接近GPT-5水平),但后续回答往往大有进步,证明部分非常令人印象深刻;多次接近完整。
鉴于Gemini和DeepSeek在代币表现上似乎也处于领先地位,我猜这可能与它们解决此类问题的能力有关。基本上是看它们在合理的计算资源限制下能走多远。
尽管基准测试结果可能并不明显,这在开源权重模型中仍然是一次巨大飞跃。为DeepSeek团队点赞!
The operating cost of adult and gambling startups #
https://news.ycombinator.com/item?id=47889668
You may have a cool product in the field of sports betting, casinos, or lotteries. But almost all social networks and search engines won’t let you advertise without a license from the required jurisdiction. Good. You should face social stigma for creating products that literally ruin people’s lives.
b40d-48b2-979e
你可能在体育博彩、赌场或彩票领域有一个很酷的产品。但几乎所有的社交网络和搜索引擎都不会允许你在没有相关辖区许可的情况下做广告。
很好。你应该因为创造了彻底毁掉人们生活的产品而受到社会的谴责。
Google plans to invest up to $40B in Anthropic #
https://news.ycombinator.com/item?id=47896920
Context: a few weeks ago, Anthropic signed a deal to buy “multiple gigawatts of next-generation TPU capacity” from Google and Broadcom 1. There have been several previous deals, too.
Some people call this sort of thing a “circular deal”, but perhaps a better way to think of it is as a very large-scale version of vendor financing? The simple version of vendor financing is when a vendor gives a retailer time to pay for goods they purchased for resale. This is effectively a loan that’s backed by the retailer’s ability to resell the goods. There’s a possibility that the retailer goes broke and doesn’t pay, but the vendor has insight into how well the retailer is doing, so they know if they’re a good risk.
Similarly, Google likely knows quite a lot about Anthropic because Anthropic buys computing services from Google for resale. They’re making an equity investment rather than a loan, but the money will be coming back to Google, assuming Anthropic’s sales continue to rise as fast as they have been.
Also, if you own Google stock, some small part of that is an investment in Anthropic?
1 https://www.anthropic.com/news/google-broadcom-partnership-compute
skybrian
几周前,Anthropic 签署了一项协议,将从 Google 和 Broadcom 购买“多千兆瓦的下一代 TPU 容量” 1。之前也有过几笔类似的交易。
有些人称这类交易为“循环交易”,但或许更好的理解是一种大规模的供应商融资?供应商融资的简单版本是供应商给零售商一定的时间来支付他们为转售购买的商品款项。这本质上是一种贷款,背书来源于零售商转售商品的能力。零售商有可能破产不付钱,但供应商可以了解零售商的经营状况,从而判断其风险是否可控。
类似地,Google 可能对 Anthropic 了解很多,因为 Anthropic 是从 Google 购买计算服务再进行转售的。他们做的是股权投资而非贷款,但只要 Anthropic 的销售额像过去一样持续快速增长,资金最终还是会回到 Google 手里。
另外,如果你持有 Google 股票,那么其中一小部分其实也是对 Anthropic 的投资。
1 https://www.anthropic.com/news/google-broadcom-partnership-compute
Google plans to invest up to $40B in Anthropic #
https://news.ycombinator.com/item?id=47896806
Where I work:
-
Development velocity is very noticeably much higher across the board. Quality is not obviously worse, but it’s LLM assisted, not vibe coding (except for experiments and internal tools).
-
Things that would have been tactically built with TypeScript are now Rust apps.
-
Things that would have been small Python scripts are full web apps and dashboards.
-
Vibe coding (with Claude Desktop, nobody is using Replit or any of the others) is the new Excel for non tech people.
-
Every time someone has any idea it’s accompanied by a multi page “Clauded” memo explaining why it’s a great idea and what exactly should be done (about 20% of which is useful).
-
80% of what were web searches now go to Claude instead (for at least a significant minority of people, could easily be over 50%).
-
Nobody talks about ChatGPT any more. It’s Claude or (sometimes) Gemini.
-
My main job isn’t writing code but I try to keep Claude Code (both my personal and corpo accounts) and OpenCode (also almost always Claude, via Copilot) busy and churning away on something as close to 100% of the time as I can without getting in the way of my other priorities.
We (~20 people) are probably using 2 orders of magnitude more inference than we were at the start of the year and it’s consolidated away from cursor, ChatGPT and Claude to just be almost all Claude (plus a little Gemini as that’s part of our Google Whateverspace plan and some people like it, mostly for non-engineering tasks).
No idea if any of this will make things better, exactly, but I think we’d be at a severe competitive disadvantage if we dropped it all and went back how things were.
barnabee
我工作的地方:
-
整体开发速度明显快了很多。质量看起来并没有明显变差,但现在是由大型语言模型辅助完成的,而不是凭感觉写代码(实验和内部工具除外)。
-
本来会用 TypeScript 战术性开发的东西,现在变成了用 Rust 开发的应用。
-
本来会写成小的 Python 脚本的东西,现在做成了完整的网络应用和仪表盘。
-
非技术人员的新“Excel”是带有 Claude Desktop 的“凭感觉写代码”,没人用 Replit 或其他工具。
-
每当有人有想法时,都会附带一份多页的“Claude”备忘录,解释为什么这是个好主意以及具体该做什么(大约 20% 内容是有用的)。
-
以前 80% 的网页搜索现在至少在一部分人群中改为用 Claude,可能超过 50%。
-
大家已经不怎么提 ChatGPT 了,现在用的是 Claude 或(偶尔)Gemini。
-
我主要工作不是写代码,但我尽力让 Claude Code(我个人和公司账户)以及 OpenCode(几乎总是通过 Copilot 用 Claude)一直保持忙碌,几乎百分之百时间都在运行代码,同时不影响我其他优先事项。
我们(大约 20 人)现在的推理调用量比年初增加了大两个数量级,且从原来的 cursor、ChatGPT 和 Claude 分散到几乎全部集中在 Claude(还有少量 Gemini,因这是我们 Google Whateverspace 计划的一部分,有些人喜欢用,主要用于非工程任务)。
不确定这些变化是否一定会让一切变得更好,但如果放弃这一切回到过去的做法,我认为我们会处于严重的竞争劣势。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886750
The incredible arrogance and hybris of the American initiated tech war - it is just a beautiful thing to see it slowly fall apart.
The US-China contest aside - it is in the application layer llms will show their value. There the field, with llm commoditization and no clear monopolies, is wide open.
There was a point in time where it looked like llms would the domain of a single well guarded monopoly - that would have been a very dark world. Luckily we are not there now and there is plenty of grounds for optimism.
chvid
美国发起的科技战争所表现出的难以置信的傲慢和自大——看到它慢慢瓦解真是一件美妙的事情。
撇开美中竞争不谈——大模型(llms)的价值将在应用层面显现。在那里,随着大模型的商品化和没有明确垄断,市场是非常开放的。
曾有一段时间,看起来大模型将成为某个单一严格把控的垄断领域——那将是一个非常黑暗的世界。幸运的是,现在情况并非如此,未来充满了许多乐观的理由。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886285
Seriously, why can’t huge companies like OpenAI and Google produce documentation that is half this good??
https://api-docs.deepseek.com/guides/thinking_mode
No BS, just a concise description of exactly what I need to write my own agent.
throwa356262
说真的,为什么像OpenAI和谷歌这样的大公司就不能出一份至少有这份文档一半好的说明文档呢?
https://api-docs.deepseek.com/guides/thinking_mode
没有废话,只有我写自己代理所需的简明说明。
Google plans to invest up to $40B in Anthropic #
https://news.ycombinator.com/item?id=47895553
I think the subtext of the last few weeks is the Anthropic was becoming severely capacity constrained (or approaching that). They seem to have had to sign two somewhat adverse contracts with Amazon and Google in short succession. suddenly model quality is back up again.
33MHz-i486
我认为这几周的潜台词是Anthropic的能力严重受限(或者接近受限)。他们似乎不得不在短时间内与亚马逊和谷歌签订了两份稍显不利的合同。突然之间,模型的质量又提升了。
Google plans to invest up to $40B in Anthropic #
https://news.ycombinator.com/item?id=47896389
We suddenly have a proliferation of new internal tools and resources, nearly all of which are barely functional and largely useless with no discernible impact on the overall business trajectory but sure do seem to help come promo time.
Barely an hour goes by without a new 4-page document about something that that everyone is apparently ment to read, digest and respond to, despite its ‘author’ having done none of those steps, it’s starting to feel actively adversarial.
msy
我们突然出现了大量新的内部工具和资源,几乎所有的工具都功能欠缺,基本没用,对整体业务走向没有明显影响,但在升职考核时似乎确实有帮助。
几乎每小时都有一份新的四页文档,内容大家显然都被要求阅读、消化并回复,尽管“作者”自己根本没做过这些步骤,这种情况开始让人感觉像是在对抗。
Firefox Has Integrated Brave’s Adblock Engine #
https://news.ycombinator.com/item?id=47899472
The Firefox team is experimenting with ways to improve the built-in Enhanced Tracking Protection feature in Firefox. This is one of the libraries we’re going to experiment with.
- We are not, and have no plans to abandon MV2 extensions. This will ensure certain types of add-ons, like ad-blockers, continue to work best in Firefox.
- Firefox supports several ad-blockers as add-ons on Desktop and Android, including uBlock Origin.
- We are not bundling Brave’s ad-blocking system, we’re testing one of their open source Rust components to improve how Firefox processes tracker lists.
This is what the official Firefox account had to say when this came up on reddit.
evilpie
Firefox团队正在尝试改进Firefox内置的增强跟踪保护功能的各种方法。这是我们将要试验的一个库。
-
我们没有,也不打算放弃MV2扩展。这将确保某些类型的插件,比如广告拦截器,能够在Firefox中继续最佳运行。
-
Firefox在桌面和安卓平台支持多种广告拦截插件,包括uBlock Origin。
-
我们并没有整合Brave的广告拦截系统,我们只是测试他们一个开源的Rust组件,以改进Firefox处理跟踪列表的方式。
Meta tells staff it will cut 10% of jobs #
https://news.ycombinator.com/item?id=47885496
People bring up “overhiring” every single time. We’ve had like 3 years of these massive layoffs already. How many “corrections” do they need?
I’m beginning to feel like the “overhiring” line is a concerted campaign
culi
每次都会有人提到“过度招聘”。我们已经经历了大约三年的大规模裁员了。他们还需要多少次“调整”?
我开始觉得“过度招聘”这句话像是一场有组织的宣传活动。
Replace IBM Quantum back end with /dev/urandom #
https://news.ycombinator.com/item?id=47897648
Project Eleven just awarded 1 BTC for “the largest quantum attack on ECC to date”, a 17-bit elliptic curve key recovered on IBM Quantum hardware. Yuval Adam replaced the quantum computer with /dev/urandom. It still recovers the key.
pigeons
Project Eleven 刚刚因“迄今为止对椭圆曲线密码学(ECC)最大的量子攻击”获得了1个比特币奖励,他们在IBM量子硬件上恢复了一个17位的椭圆曲线密钥。Yuval Adam 用 /dev/urandom 替换了量子计算机,依然能够恢复该密钥。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47886569
As a Brit I’m here for it to be honest, I’m tired of America with everything that’s going on.
China is not perfect but a bit of competition is healthy and needed
ifwinterco
作为英国人,说实话我支持这个,我已经对美国发生的一切感到厌倦。
中国并不完美,但一些竞争是健康且必要的。
Google plans to invest up to $40B in Anthropic #
https://news.ycombinator.com/item?id=47895911
That’s what’s needed when you go from $9B in ARR … to $30B in ARR literally just one quarter later.
That kind of insane growth & demand is unprecedented at that scale.
https://www.anthropic.com/news/google-broadcom-partnership-compute
tiffanyh
当你的年经常性收入从90亿美元……在短短一个季度内飙升到300亿美元时,这正是所需要的。
如此疯狂的增长和需求,在如此规模上是前所未有的。
https://www.anthropic.com/news/google-broadcom-partnership-compute
Sabotaging projects by overthinking, scope creep, … #
https://news.ycombinator.com/item?id=47891379
Day 1: We aim to demonstrate the effectiveness of an existing industrial catalyst in a novel application that has not seen commercial usage, potentially lowering cost of production of precursors for essential medications
Day 400: Having thoroughly described a universal theory of everything, we set out to build an experimental apparatus in orbit at a Lagrange point capable of detecting a universal particle which acts a mediator for all observable forces in the known universe.
sidewndr46
第1天:我们旨在证明一种现有的工业催化剂在一种尚未商业化应用的新领域中的有效性,可能降低关键药物前体的生产成本。
第400天:在详细描述了一个万物统一理论后,我们着手在拉格朗日点建造一个轨道实验装置,能够检测一种作为已知宇宙所有可观测力的媒介的普适粒子。
Replace IBM Quantum back end with /dev/urandom #
https://news.ycombinator.com/item?id=47898716
This was exactly the premise of my sigbovik April Fool’s paper in 2025 1: for small numbers, Shor’s algorithm succeeds quickly when fed random samples. And when your circuit is too long (given the error rate of the quantum computer), the quantum computer imitates a random number generator. So it’s trivial to “do the right thing” and succeed for the wrong reason. It’s one of the many things that make small factoring/ecdlp cases bad benchmarks for progress in quantum computing.
I warned the project11 people that this would happen. That they’d be awarding the bitcoin to whoever best obfuscated that the quantum computer was not contributing (likely including the submitter fooling themselves). I guess they didn’t take it to heart.
Strilanc
这正是我在2025年sigbovik愚人节论文 1中的论点:对于小数字,当输入随机样本时,Shor算法能快速成功。而当你的电路太长(考虑到量子计算机的错误率),量子计算机其实变成了随机数生成器的模拟。所以“做对了事”却因错误的原因成功,这很容易做到。这也是许多因素之一,说明小规模的分解因子或椭圆曲线离散对数问题并不适合作为量子计算进展的基准。
我曾警告project11的人这会发生。他们会把比特币奖励给那些最能掩饰量子计算机并未真正贡献的人(很可能包括提交者自己骗自己)。看来他们并不把这当回事。
I cancelled Claude: Token issues, declining qualit… #
https://news.ycombinator.com/item?id=47892744
I feel like I’m using Claude Opus pretty effectively and I’m honestly not running up against limits in my mid-tier subscriptions. My workflow is more “copilot” than “autopilot”, in that I craft prompts for contained tasks and review nearly everything, so it’s pretty light compared to people doing vibe coding.
The market-leading technology is pretty close to “good enough” for how I’m using it. I look forward to the day when LLM-assisted coding is commoditized. I could really go for an open source model based on properly licensed code.
rectang
我觉得我使用Claude Opus相当有效,老实说,在我的中级订阅中并没有遇到限制。我的工作流程更像是“辅助驾驶”而非“自动驾驶”,也就是说我会为具体任务设计提示,并且几乎审查所有内容,所以相较于那些进行代码调试的人来说,我的工作量还是比较轻松的。
目前市场领先的技术对于我的使用场景来说已经差不多“足够好了”。我期待有一天LLM辅助编程能够变成一种商品化服务。我非常希望出现一个基于合法授权代码的开源模型。
Sabotaging projects by overthinking, scope creep, … #
https://news.ycombinator.com/item?id=47891121
Incidentally, this describes what I believe to be the great difficulty of PhD research. You have to take a topic you find interesting and read all possible related work in it, which tends to result in significant scope creep as you realize just how much there is that already does you want to do. Having exhausted your initial energy and excitement for the project, you have to force yourself the remaining 20-30% of he way to the finish line to get that work to a publishable state.
bennettnate5
顺便说一句,这正好描述了我认为博士研究的最大难点。你必须选择一个自己感兴趣的课题,阅读所有相关的已有研究,这通常会导致研究范围不断扩大,因为你会意识到已有的工作远比你想做的要多得多。在耗尽了最初的动力和兴奋后,你必须强迫自己坚持完成剩下20%到30%的工作,才能使研究成果达到可发表的状态。
US special forces soldier arrested after allegedly… #
https://news.ycombinator.com/item?id=47883404
Nabbing the little guy for show, very much like Henry Hill taking one for Paulie and the gang. The same gang that robbed the Lufthansa vault at JFK Airport, stealing six million dollars in cash and jewelry.
When the history of this administration is written, provided that history itself has not been completely rewritten a la “1984,” Goodfellas will be required reading/watching.
And the highly profitable daily mood-induced oil price bets will just be forgotten.
Wilhoit’s Law:
Wilhoit’s law.
“Conservatism consists of exactly one proposition, to wit: There must be in-groups whom the law protects but does not bind, alongside out-groups whom the law binds but does not protect.”
https://pylimitics.net/wilhoits-law/
k310
抓住这个小人物来作展示,非常像亨利·希尔(Henry Hill)为了保利(Paulie)和帮派承担责任。正是那个帮派抢劫了JFK机场的汉莎航空保险库,偷走了价值六百万美元的现金和珠宝。
当这届政府的历史被书写时,前提是历史本身没有像《1984》那样被彻底篡改,《好家伙》(Goodfellas)将成为必读/必看之作。
而那些由日常情绪驱动的高利润石油价格押注则会被遗忘。
威尔霍特定律:
威尔霍特定律。
“保守主义正是由一个命题组成,那就是:必须存在法律保护但不约束的内团体,同时还有法律约束但不保护的外团体。”
There Will Be a Scientific Theory of Deep Learning #
https://news.ycombinator.com/item?id=47896190
The inflection point was 2012, when AlexNet [0], a deep convolutional neural net, achieved a step-change improvement in the ImageNet classification competition.
After seeing AlexNet’s results, all of the major ML imaging labs switched to deep CNNs, and other approaches almost completely disappeared from SOTA imaging competitions. Over the next few years, deep neural networks took over in other ML domains as well.
The conventional wisdom is that it was the combination of (1) exponentially more compute than in earlier eras with (2) exponentially larger, high-quality datasets (e.g., the curated and hand-labeled ImageNet set) that finally allowed deep neural networks to shine.
The development of “attention” was particularly valuable in learning complex relationships among somewhat freely ordered sequential data like text, but I think most ML people now think of neural-network architectures as being, essentially, choices of tradeoffs that facilitate learning in one context or another when data and compute are in short supply, but not as being fundamental to learning. The “bitter lesson” 1 is that more compute and more data eventually beats better models that don’t scale.
Consider this: humans have on the order of 10^11 neurons in their body, dogs have 10^9, and mice have 10^7. What jumps out at me about those numbers is that they’re all big. Even a mouse needs hundreds of millions of neurons to do what a mouse does.
Intelligence, even of a limited sort, seems to emerge only after crossing a high threshold of compute capacity. Probably this has to do with the need for a lot of parameters to deal with the intrinsic complexity of a complex learning environment. (Mice and men both exist in the same physical reality.)
On the other hand, we know many simple techniques with low parameter counts that work well (or are even proved to be optimal) on simple or stylized problems. “Learning” and “intelligence”, in the way we use the words, tends to imply a complex environment, and complexity by its nature requires a large number of parameters to model.
pash
转折点是在2012年,当时AlexNet[0],一个深度卷积神经网络,在ImageNet分类比赛中实现了质的飞跃。
看到AlexNet的成果后,所有主要的机器学习图像实验室都转向了深度卷积神经网络,其他方法几乎完全从最先进的图像竞赛中消失了。在接下来的几年里,深度神经网络也逐渐主导了其他机器学习领域。
普遍的看法是,正是(1)比以往指数级增长的计算能力和(2)指数级增长的高质量数据集(如经过精心策划和人工标注的ImageNet数据集)的结合,最终让深度神经网络得以大放异彩。
“注意力机制”的发展在学习诸如文本这类顺序性较强且顺序较自由的数据中的复杂关系时尤其有价值,但我认为现在大多数机器学习专家认为神经网络架构本质上是为了在数据和计算资源有限的情况下,实现不同场景下学习的权衡选择,而不是学习的根本原理。“苦难教训” 1是,更多的计算资源和更多的数据最终会击败那些不能扩展的更优模型。
考虑一下:人类大约有10^11个神经元,狗有10^9个,老鼠有10^7个。我关注的是这些数字都很大。即使是老鼠,也需要数亿个神经元来完成它们的行为。
即使是有限的智能,似乎也只有在计算能力超过某个高阈值后才会出现。可能这是因为复杂学习环境本质上的复杂性需求大量参数来处理。(老鼠和人类都存在于相同的物理现实中。)
另一方面,我们知道许多参数数量较少的简单技术在简单或程式化的问题上效果很好,甚至被证明是最优的。“学习”和“智能”这两个词通常意味着一个复杂的环境,而复杂性本质上需要大量参数来建模。
I’m done making desktop applications (2009) #
https://news.ycombinator.com/item?id=47892332
Almost all of Patrick’s points are great if your software development goal is to make a buck. They don’t seem to matter if you’re writing open source, and I’d argue that desktop apps are still relevant and wonderful in the open source world. I just started a new hobby project, and am doing it as a cross-platform, non-Electron, desktop app because that’s what I like to develop.
The onboarding funnel: Only a concern if you’re trying to grow your user base and make sales.
Conversion: Only a concern if you’re charging money.
Adwords: Only a concern if, in his words, you’re trying to “trounce my competitors”.
Support: If you’re selling your software, you kind of have to support it. Minor concern for free and open source.
Piracy: Commercial software concern only.
Analytics and Per-user behavior: Again, only commercial software seems to feel the need to spy on users and use them as A/B testing guinea pigs.
The only point I can agree with him that makes web development better is the shorter development cycles. But I would argue that this is only a “developer convenience” and doesn’t really matter to users (in fact, shorter development cycles can be worse for users as their software changes rapidly like quicksand out from under them.) To me, in my open source projects, my “development cycle” ends when I push to git, and that can be done as often as I want.
ryandrake
几乎所有Patrick的观点在你以赚钱为目标的软件开发中都很有价值。如果你是在写开源软件,这些观点似乎并不适用。我还认为桌面应用在开源世界依然重要且出色。我刚开始了一个新的业余项目,做的是跨平台的非Electron桌面应用,因为这正是我喜欢开发的类型。
用户引导流程:只有在你想扩大用户群并增加销售时才是问题。
转化率:只有在你收费时才是问题。
Adwords广告:只有在他所谓的“击败竞争对手”时才是问题。
支持服务:如果你卖软件,你必须提供支持。对于免费和开源软件来说,这只是个次要问题。
盗版:只关乎商业软件。
分析和每用户行为跟踪:同样,只有商业软件才会觉得需要监控用户,把他们当成A/B测试的试验对象。
我唯一同意他的让网页开发更好的点是更短的开发周期。但我认为这只是“开发者的方便”,对用户并不重要(事实上,更短的开发周期可能对用户更糟,因为软件像流沙一样迅速变化,让用户难以适应)。对我来说,在我的开源项目里,我的“开发周期”就是我什么时候推送到git,这可以随时进行。
DeepSeek v4 #
https://news.ycombinator.com/item?id=47892830
Also, note that there’s zero CUDA dependency. It runs entirely on Huawei chips.
That is a huge claim to make with no evidence.
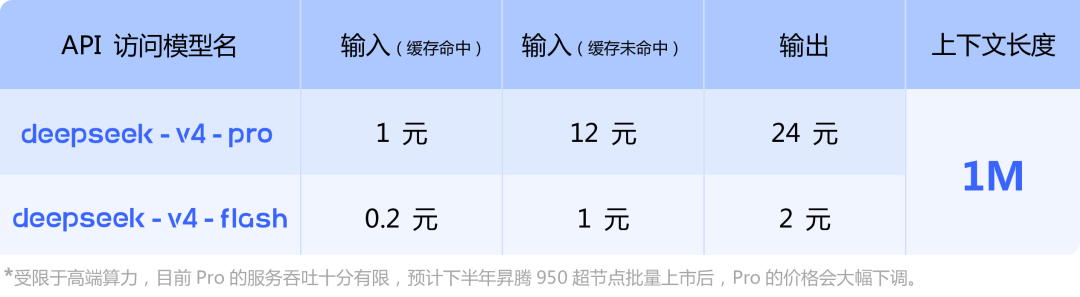
I researched what you said, and I have found no statement to that effect in their paper[0], on huggingface 1, twitter[2], WeChat[3], or in their news release[4].
They only mention as a footnote in only the Chinese version of their news release that they plan to reduce inference costs with the Ascend 950 supernode when it releases[5]. The only mention of Huawei in their paper is that they validated a technique to lower interconnect bandwidth on Ascend NPUs and Nvidia GPUs[6].
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
1 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] https://xcancel.com/deepseek_ai/status/2047516922263285776
[3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg
[4] https://api-docs.deepseek.com/news/news260424
[5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png
{kind=link}
[6] Page 16
nabakin
另外,请注意这里完全没有CUDA依赖。它完全运行在华为芯片上。
这是一个没有任何证据的大声明。
我调查了你说的内容,但在他们的论文[0]、huggingface页面 1、推特[2]、微信[3]以及新闻发布[4]中都没有找到类似表述。
他们只是在新闻发布的中文版脚注中提到,计划在Ascend 950超级节点发布时降低推理成本[5]。他们论文中唯一提到华为的是验证了一种降低Ascend NPU和Nvidia GPU之间互连带宽的技术[6]。
[0] https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
1 https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
[2] https://xcancel.com/deepseek_ai/status/2047516922263285776
[3] https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg
[4] https://api-docs.deepseek.com/news/news260424
[5] https://api-docs.deepseek.com/zh-cn/img/v4-price.png
[6] 第16页
Meta tells staff it will cut 10% of jobs #
https://news.ycombinator.com/item?id=47885904
It’s #3 - it’s always #3.
All of these tech companies (with perhaps the notable exception of Apple) massively overhired during the pandemic, and that overhiring was on top of a decade+ of the ZIRP era. So there are 2 main drivers of these layoffs:
-
Correcting pandemic overhiring
-
In the ~2010-2022 timeframe, tech companies poured all this money into speculative bets that never went anywhere, at least from a profit perspective (think Amazon’s Alexa devices division, Google Stadia, and perhaps most famously the Metaverse itself). All those diversions are now toast, and they employed a ton of people. The only speculative bet that is now “allowed” is AI, which is one reason why I giggle whenever I hear people trying to defend their companies or projects by adding “AI” somewhere in the name.
So perhaps my second point is similar to your #2, but I think the important difference is that the end of the ZIRP era would have caused companies to kill these inherently unprofitable projects even if AI never came on the scene.
hn_throwaway_99
是第三条——永远都是第三条。
所有这些科技公司(或许苹果是个例外)在疫情期间大规模招聘,而这次过度招聘是在十多年零利率政策(ZIRP)时代的基础上进行的。所以这次裁员有两个主要原因:
-
纠正疫情期间的过度招聘
-
在大约2010年至2022年间,科技公司将大量资金投入到一些从盈利角度看从未成功的投机项目中(比如亚马逊的Alexa设备部门、谷歌Stadia,可能最著名的是元宇宙本身)。所有这些偏离主业的项目现在都失败了,而且它们雇佣了很多人。唯一现在“被允许”的投机项目是人工智能,这也是为什么每当有人试图通过在公司或项目名称中加入“AI”来为其辩护时,我都会忍俊不禁。
所以我第二点可能和你说的第二点类似,但我认为,关键的区别是,即使人工智能从未出现,ZIRP时代结束也会促使公司关闭这些本质上不盈利的项目。